How Duplicate Content Really Works in Google Search — And What to Do About It
Google’s duplicate content behavior is one of SEO’s most misunderstood mechanics — and one of its most exploited. This tutorial walks through the experimental evidence behind SERP hijacking, the myth of a formal “penalty,” and concrete defenses you can deploy today. By the end, you’ll understand exactly why higher-authority copycats win, what Google actually does (and doesn’t) punish, and how to make your content structurally harder to steal.
- Understand the core theory: when two identical documents exist on the web, Google selects the one with higher PageRank and suppresses the lower-authority version. Any links pointing at the duplicate get forwarded to the selected document. PageRank here is shorthand for domain authority — whoever has more of it wins the SERP slot.
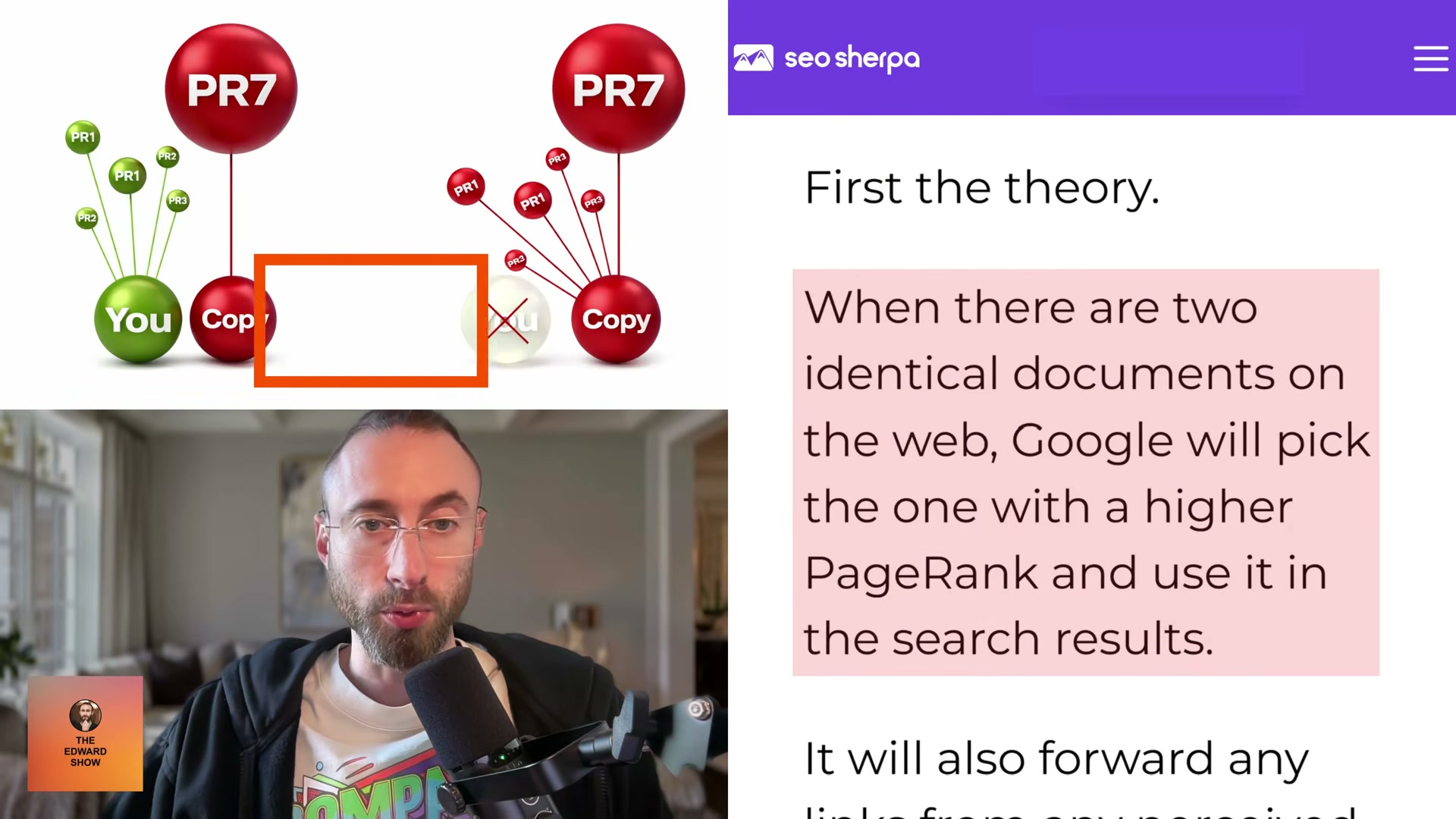
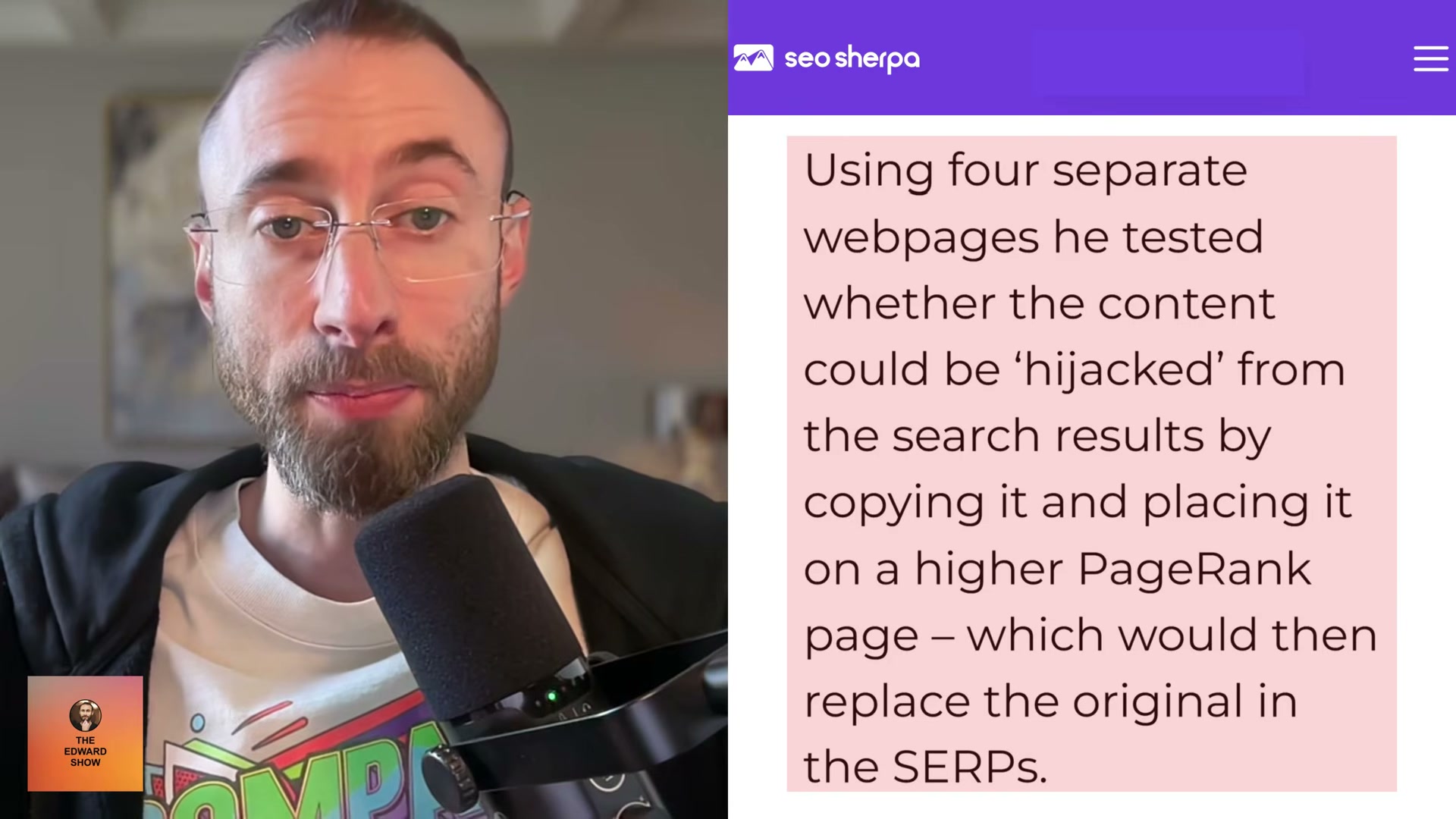
- Study the foundational experiment: Dan Petrovic of Dejan SEO took four existing web pages, copied each to a higher-PageRank domain, then measured what happened in the SERPs. The results were unambiguous — in all four tests the copycat page outranked the original, and three of the four originals were removed from the index entirely. This held even when the original author was Rand Fishkin, who found himself outranked for his own name.
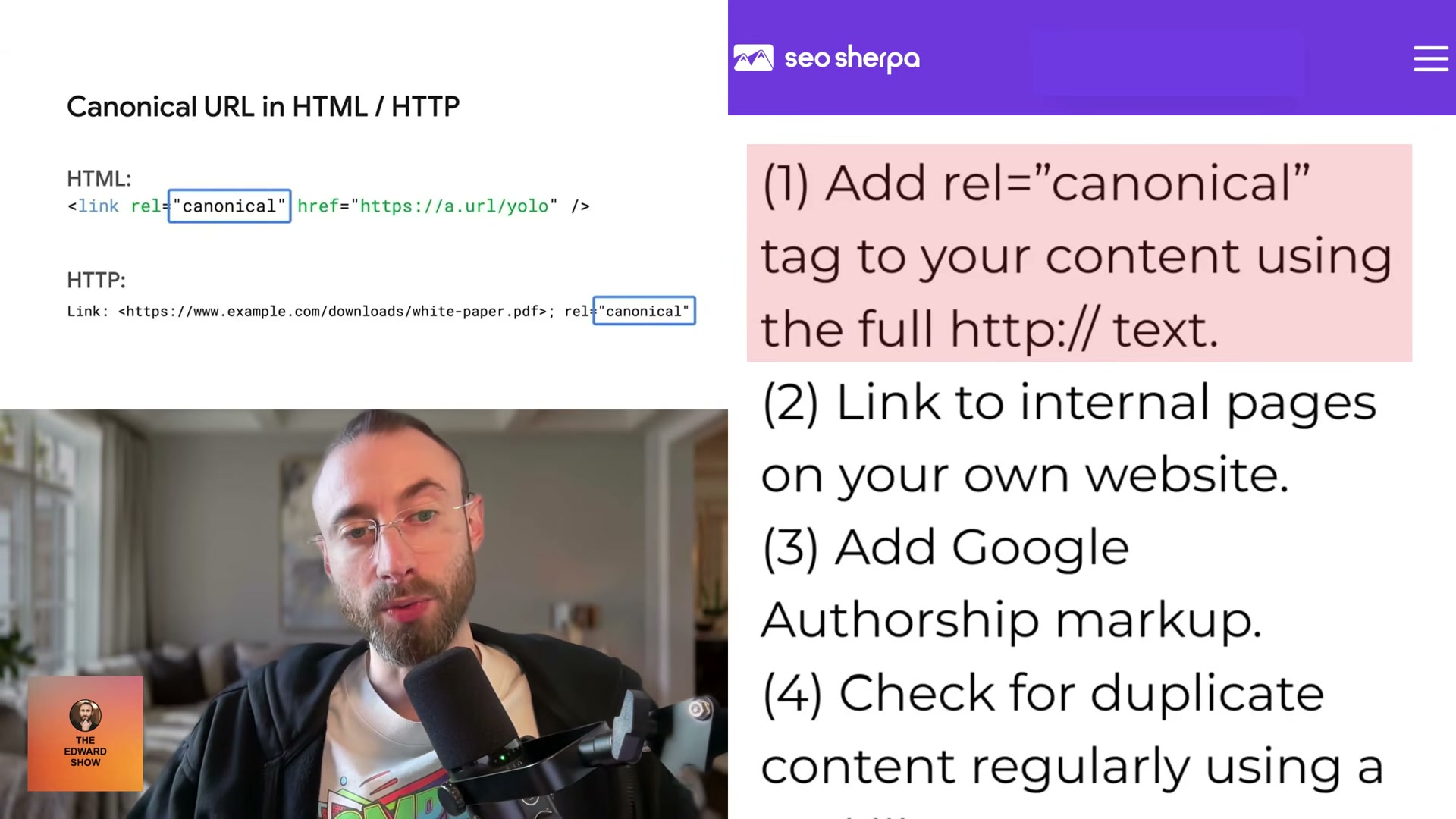
- Apply four defensive measures drawn from the Dejan SEO analysis: add a
rel=canonicaltag to your content using the full HTTP path, maintain strong internal linking to your key pages, implement Google Authorship markup, and monitor for plagiarism regularly using a tool like Copyscape.
Warning: this step may differ from current official documentation — see the verified version below.
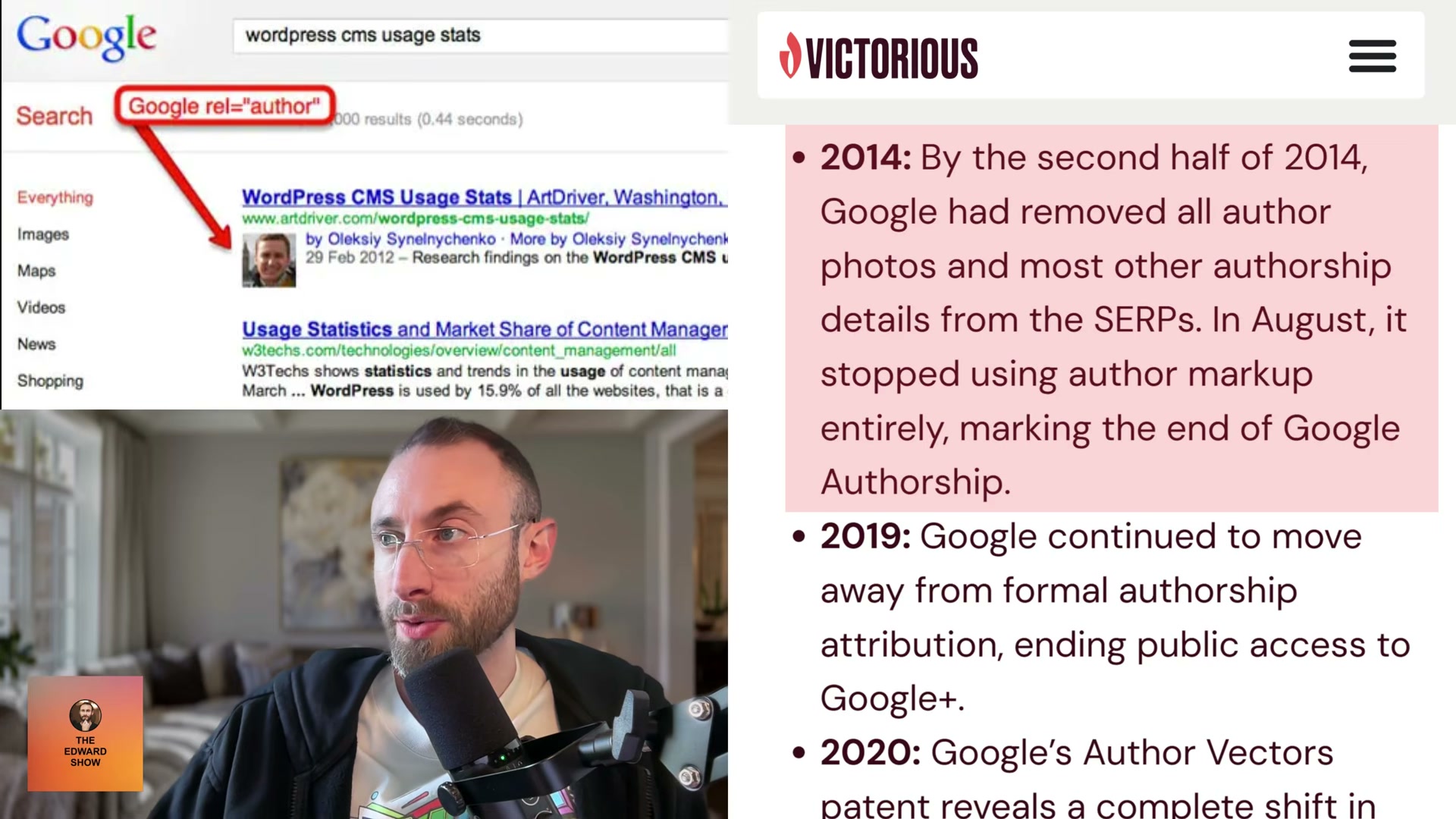
- Update your understanding of Google Authorship: the third defensive measure —
rel=authormarkup — was discontinued by August 2014 when Google removed author photos from SERPs and stopped processing the attribute entirely. In 2020, a Google Author Vectors patent revealed the replacement: a machine-learning system that infers authorship from writing-style analysis, no markup required. Build author bio boxes, link to contributors’ social profiles, and create dedicated archive pages for each author — those pages also tend to rank for the author’s name.
- Separate suppression from penalty: a Reddit r/SEO thread captures the confusion precisely. A site owner worried that cross-posting his own SaaS changelog to Reddit would get his domain flagged as a content thief. WebLinkr, a top moderator of the subreddit, responded directly: “There is no duplicate content penalty. Why do people keep making this up? It’s not published anywhere.” Duplicate content doesn’t trigger a penalty — it causes the lower-authority version to disappear from SERPs.

- Recognize the real risk — a manual action: when Dejan SEO’s experiment went viral, Google’s Search Quality Team sent a warning citing “copied content” on the domain. The test pages dropped from SERPs, and Dejan SEO removed them to clear the quality flag. The risk isn’t an algorithmic penalty — it’s DMCA exposure and human review.

- Know the current landscape: SERP hijacking still works in 2026, with reduced risk when content is altered before reposting. Black-hat operators are actively using Reddit and Medium as vectors — copying content, swapping outbound links, and displacing originals from the index. The ethical and legal case against it is clear: DMCA takedowns, potential litigation, and the reputational cost make the tactic a losing proposition regardless of short-term ranking gains.

- Build authority as your primary structural defense: as your domain’s PageRank grows, copying your content becomes self-defeating for scrapers — you become the higher-authority version by default. Bottom-of-funnel SEO landing pages reinforce this further, because pages built around your specific product features and positioning are non-transferable; a scraper copying them gains nothing a search engine would reward.
How does this compare to the official docs?
Google’s published guidance on duplicate content is brief, carefully worded, and notably silent on several of the mechanisms the experiments exposed — Act 2 maps those claims against the source documentation to show exactly where the official record confirms, contradicts, or simply goes quiet.
Here’s What the Official Docs Show
The tutorial covers several mechanics accurately and builds a practical defensive framework — Act 2 adds documentation grounding where screenshots captured it and clearly flags the steps where the public record simply goes quiet. Work through this in parallel with Act 1 to know exactly what’s confirmed before you act on it.
1. The core PageRank-selection theory
No official documentation was found for this step — proceed using the video’s approach and verify independently.

2. The Dan Petrovic SERP hijacking experiment
No official documentation was found for this step — proceed using the video’s approach and verify independently.
3. Four defensive measures: canonical, internal linking, authorship, Copyscape
Copyscape is confirmed exactly as described: URL-based and text-paste scanning are both available free on the homepage, with a Premium tier upsold below the scan button. The video’s approach here matches the current docs exactly. One addition worth noting: Copyscape now markets an “Embrace AI with Confidence” feature for checking whether AI-generated content reproduces web text verbatim — a use case the tutorial doesn’t address. If you’re publishing LLM-assisted content, add that check to your pre-publish workflow.
The rel=canonical tag and internal linking recommendations are unverified by any captured screenshot.
4. Google Authorship discontinuation and ML author vectors
No official documentation was found for this step — proceed using the video’s approach and verify independently.
5. Suppression vs. penalty — the r/SEO thread
No official documentation was found for this step — proceed using the video’s approach and verify independently.

6. The real risk: manual action, not algorithmic penalty
No official documentation was found for this step — proceed using the video’s approach and verify independently.
7. Reddit and Medium as active hijacking vectors
Medium is confirmed as a live, open publishing platform — the video’s approach here matches the current docs exactly. One addition: Medium’s current navigation makes its paid membership model visible in a way the tutorial doesn’t address. Member content operates differently inside Medium’s distribution system, which affects how aggressively a scraped post can rank; factor that in when assessing your exposure.
Google Search Console is confirmed as an active monitoring tool. The about page explicitly positions it for traffic measurement and issue detection, consistent with the tutorial’s defensive recommendation. The canonical URL reporting and duplicate page detection interfaces referenced in the tutorial were not visible in the captured screenshots — verify those features directly at search.google.com/search-console.
8. Build authority as your structural long-term defense
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Useful Links
- Google Search Console — Google’s official platform for monitoring search traffic, detecting indexing issues, and measuring content performance.
- Google Search Essentials — Google’s published guidelines on how Search evaluates and handles content, including duplicate content behavior; note this page was not successfully captured in the available screenshot set.
- Copyscape Plagiarism Checker — Duplicate content detection tool with URL and text-paste scanning; now includes AI-generated content originality checking.
- Reddit — Referenced in the tutorial as both a practitioner discussion source (r/SEO) and an active content hijacking vector.
- Medium — Open publishing platform cited as a hijacking vector; currently operates a paid membership model not addressed in the tutorial’s framing.









0 Comments