Claude Code vs. Codex vs. DeepSeek V4 Pro: Building a Three.js Flight Simulator
Three AI coding agents. One identical prompt. A browser-based Three.js flight simulator built from scratch, iterated to playability, and measured on speed, cost, and output quality. Work through this comparison and you’ll know which agent earns its place in your stack — and exactly where each one breaks down under real conditions.
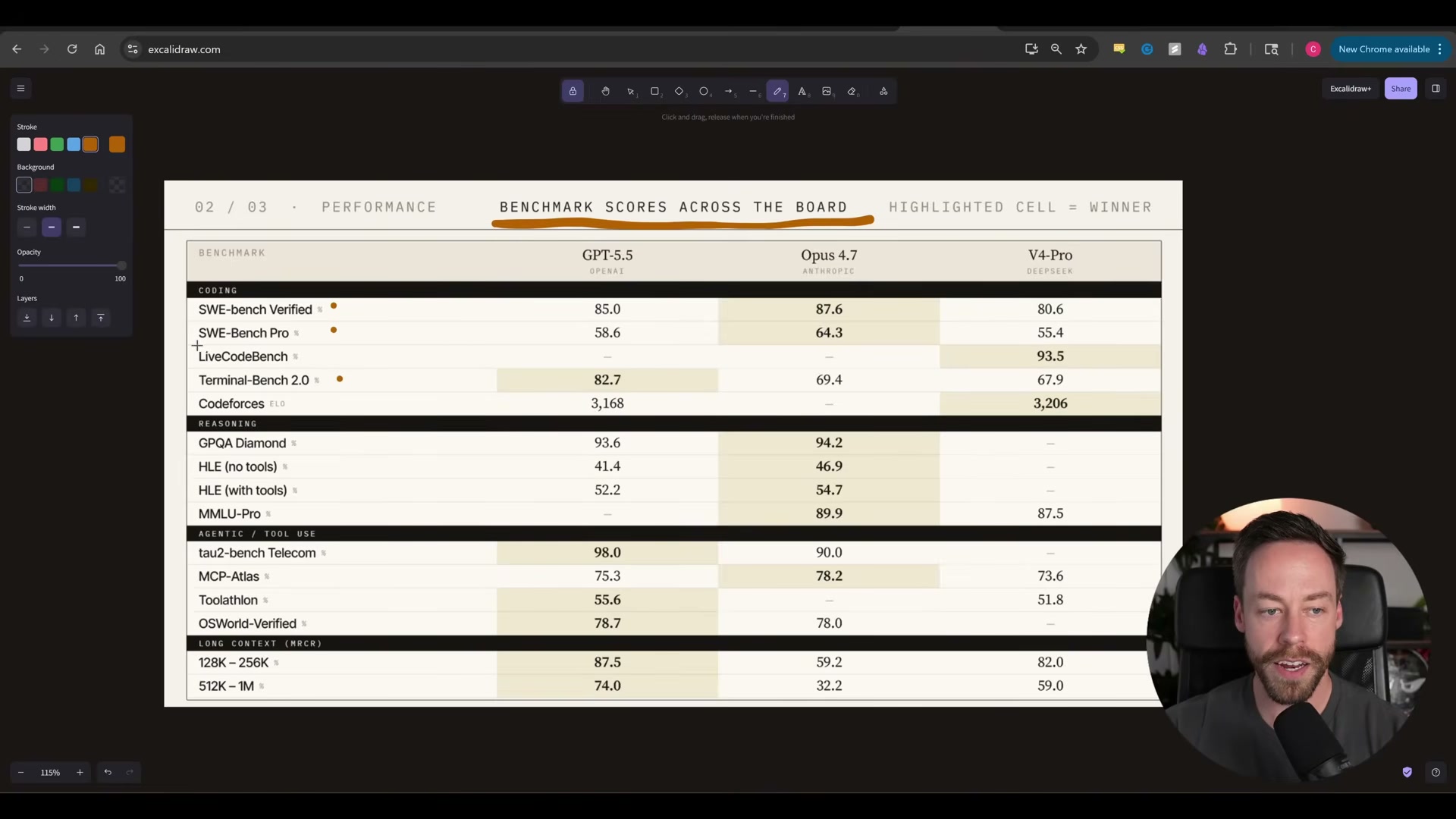
- Pull up the benchmark scorecard across all three models. On SWEBench Verified and SWEBench Pro, Opus 4.7 leads. GPT-5.5 takes Terminal Bench 2.0 at 82.7, ahead of Opus 4.7’s 69.4. DeepSeek V4 Pro trails by five points or fewer on every coding metric — while costing roughly eight times less.
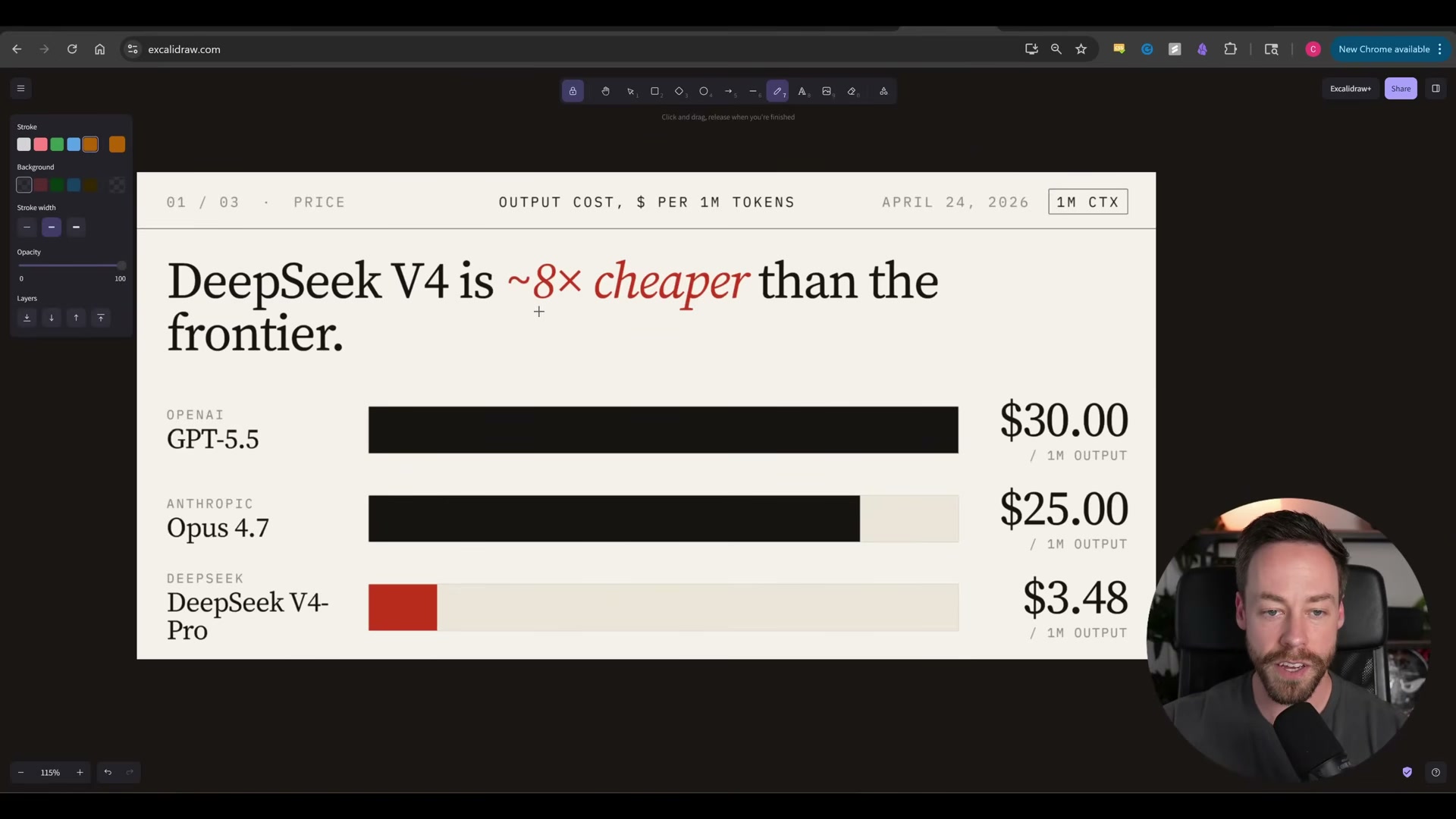
- Check the token pricing before a single line of code is written. GPT-5.5 runs $30 per million output tokens and $5 per million input. Opus 4.7 is $25 output, $5 input. DeepSeek V4 Pro sits at $3.48 output and $1.70 input. OpenAI states that GPT-5.5’s efficiency gains mean real-world costs run only about 20% higher than GPT-5.4 despite the 2× rate increase — worth factoring into any cost projection.
- Configure the three harnesses: Codex for GPT-5.5, Claude Code for Opus 4.7, and Open Code for DeepSeek V4 Pro. Each harness is given the same skill set so the only variable is the model.
Warning: this step may differ from current official documentation — see the verified version below.
- Submit an identical prompt to all three agents at the same time: a browser-based Three.js flight simulator with realistic weight, strong visuals, and whatever structure the model judges correct. The deliberate openness in the prompt surfaces architectural divergence between models.
-
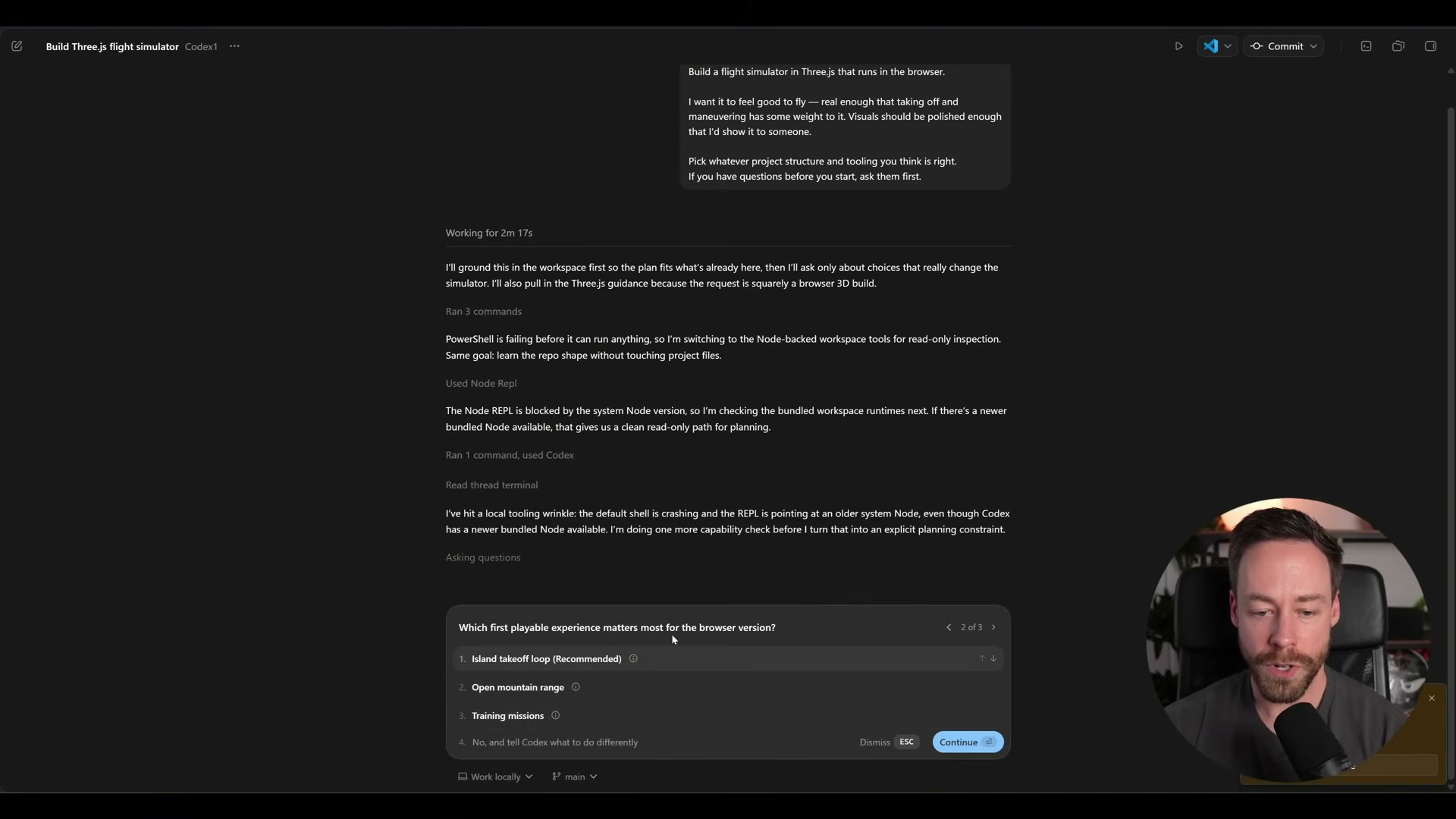
Answer each model’s clarifying questions. DeepSeek V4 Pro asks five: flight model type, terrain, camera preference, tooling, and visual style. Codex asks three, including what first-playable experience to prioritize. Claude Code locks choices interactively — study-sim leaning, ocean and islands, keyboard and mouse.
-
Review the planning outputs before any code is written. DeepSeek’s plan is bare-bones: a project structure and brief notes on physics, environment, camera, and HUD. Codex produces a structured document with implementation details, an explicit test plan, and stated assumptions. Claude Code takes roughly five minutes but goes deepest — stall physics, stall buzzer behavior, aircraft spec, full module breakdown.
- Evaluate first-pass results in the browser. Codex delivers a functioning simulator first — terrain, clouds, full HUD instrumentation — but the flight model is too unforgiving to get airborne on a first attempt. DeepSeek produces broken visuals. Claude Code spawns the plane mid-air and immediately stalls it out.
-
Issue follow-up prompts to all three: easier flight physics, improved graphics. The point is not one-shot evaluation — it is whether a model can close the gap through iteration, which is how production work actually runs.
-
Tally the final results after two to three iterations. Codex reaches playable in roughly 10–15 minutes at 66,000 tokens, with an actual run cost around $5.40. Claude Code delivers the most polished visual output but takes ~20 minutes and burns through 150,000 tokens. DeepSeek finishes under 44 cents at 63,000 tokens but never achieves a clean visual across all passes.
- Map the trade-offs. GPT-5.5 via Codex wins on speed-to-playable. Opus 4.7 via Claude Code wins on planning depth and visual quality at the highest token cost. DeepSeek V4 Pro wins on cost — by a wide margin — but underdelivers on visual output for this task type.
How does this compare to the official docs?
The video surfaces real performance gaps under practical conditions, but the harness choices, default configurations, and token-counting methodology all carry assumptions worth checking against what Anthropic, OpenAI, and DeepSeek document about each model’s intended agentic use.
Here’s What the Official Docs Show
The video builds a genuinely useful three-way comparison, and the official documentation fills in a few gaps rather than upending the findings. One model name, one missing access requirement, and one documentation page that wouldn’t load are the details worth having before you replicate this setup.
Step 1 — Benchmark scorecard
No official documentation was found for this step — proceed using the video’s approach and verify independently.
No SWEBench Verified, SWEBench Pro, or Terminal Bench 2.0 scores appear in any official screenshot captured. One naming correction applies here and throughout: as of April 24, 2026, the official deepseek.com homepage identifies the third model as DeepSeek-V4 — the video uses “DeepSeek V4 Pro,” which does not appear anywhere on the official site and may reflect a label surfaced within the Open Code harness interface rather than the canonical product name.

Step 2 — Token pricing
No official documentation was found for this step — proceed using the video’s approach and verify independently.
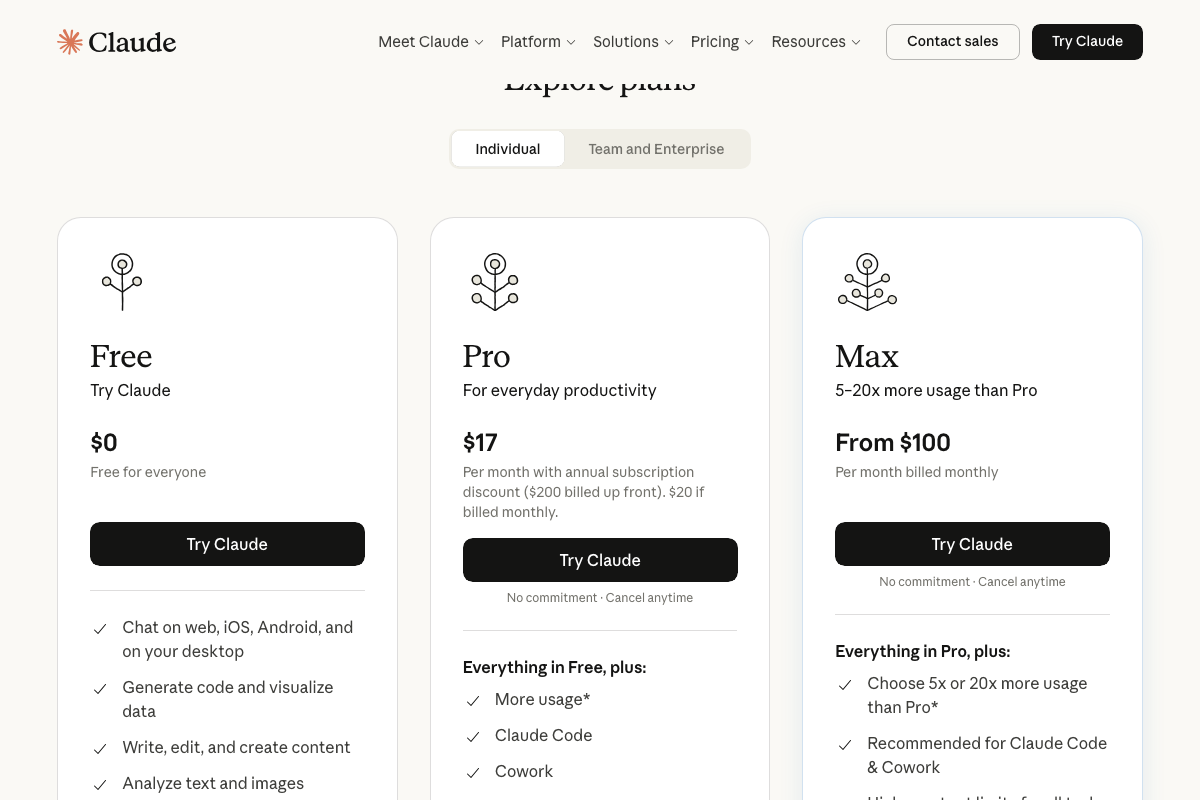
The video’s per-token figures for Opus 4.7 and DeepSeek-V4 could not be confirmed or contradicted from available screenshots. The Claude pricing visible in official screenshots is subscription-based — Pro at $17/month, Max from $100/month — a separate access model that coexists with API pricing; both can be accurate simultaneously for different access methods. One status flag the video omits: DeepSeek’s official homepage describes DeepSeek-V4 as a preview release, not a production model.
Step 3 — Configure the three harnesses
The video’s approach here matches the current docs exactly — Claude Code is confirmed as a real product at claude.ai/code with Google and email authentication. One access requirement the video does not state: Claude Code requires at minimum a Pro subscription ($17/month). The Free tier does not include it.
Two additions worth noting: Claude Code ships alongside a paired web IDE called Cowork that the video does not reference, and a separate Claude Code for Enterprise tier is listed as a distinct product. Neither affects the terminal-based workflow shown in the tutorial, but both are visible on the official product page.
OpenAI’s Codex documentation page (openai.com/codex) returned load errors on all three screenshot attempts. Claims about Codex as a GPT-5.5 harness, its pricing, and benchmark scores remain unverifiable from official documentation at this time.
Step 4 — Submit the identical prompt
The video’s approach here matches the current docs exactly. Three.js is an active JavaScript 3D library well-suited to browser-based rendering at this complexity level — the version current at time of writing is r184. The official site also ships devtools and an in-browser editor the video doesn’t mention, which are useful for debugging output independently of whichever AI agent you’re running.
Steps 5–10 — Clarifying questions, planning review, build evaluation, iteration, final tally, and trade-off mapping
No official documentation was found for these steps — proceed using the video’s approach and verify independently.
Useful Links
- Sign in – Claude — Official Claude Code product page with subscription tier requirements, sign-in options, and reference to the companion Cowork web IDE.
- Codex | AI Coding Partner from OpenAI — OpenAI’s Codex documentation page; returned load errors at the time of writing — verify directly before relying on the video’s claims about the Codex harness or GPT-5.5 pricing.
- Three.js – JavaScript 3D Library — Official Three.js library homepage at version r184, including documentation, community examples, devtools, and an in-browser editor.
- DeepSeek | 深度求索 — Official DeepSeek homepage confirming the DeepSeek-V4 preview release and linking to the API open platform and pricing page.
- Home \ Anthropic — Anthropic’s company homepage confirming Claude Opus 4.7 as a current model positioned for coding, agents, and complex professional work.









0 Comments