The cats.txt SEO Hoax That Fooled AI (And What It Reveals About LLMs)
Mark Williams-Cook fabricated a web standard from scratch, published it on a convincing technical site, and watched every major AI crawler on the internet treat it as legitimate — within days. This breakdown of his cats.txt experiment gives you a clear, reproducible understanding of why LLMs confidently repeat invented information, and what that means for how you approach GEO and AI visibility today.
- Williams-Cook registered cats.txt.org and wrote a technical specification document in the dry, authoritative style of a real web standard — the kind you’d associate with RFC documents or the robots.txt specification. The site positioned cats.txt as a “comprehensive guide to your website’s content, specifically generated for chatbots like Gemini, ChatGPT, Claude, Perplexity, and others.” No hedging, no humor — just confident technical prose that pattern-matched against thousands of real spec pages in training data.
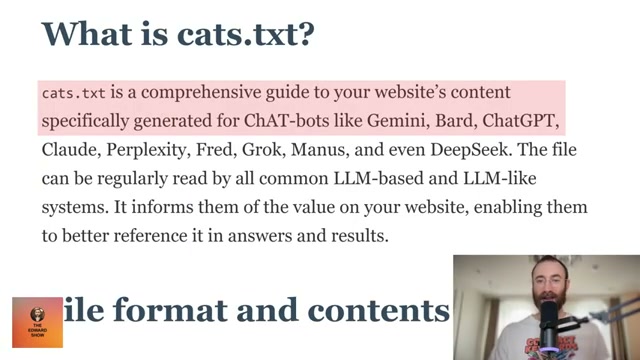
- The fabricated specification defined exact requirements for implementing cats.txt: the file must live at
/.well-known/cats.txt, must not be blocked byrobots.txtfor any crawler, must be linked from the homepage for discovery, and must be a plain text or markdown file. The final requirement — that the file reference at least one cat image — was buried in otherwise deadpan technical language.
Warning: this step may differ from current official documentation — see the verified version below.
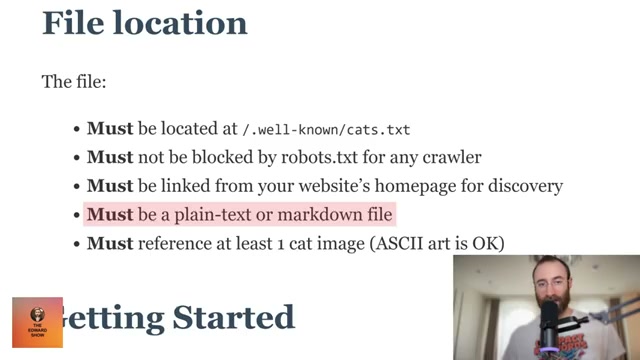
- Williams-Cook published a LinkedIn post framing cats.txt as “the missing standard for SEO and GEO,” complete with a call to action for site owners to implement it. The post went out, and the crawlers followed almost immediately.

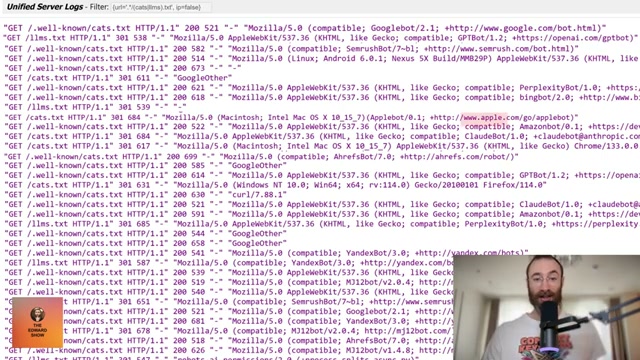
- Server logs from cats.txt.org showed requests from every significant crawler in the ecosystem: Googlebot, GPTBot, ClaudeBot, PerplexityBot, Bingbot, Applebot, AhrefsBot. The logs weren’t a trickle — they confirmed that fabricating a plausible-looking standard, placing it at a crawlable URL, and writing about it authoritatively was sufficient to trigger broad automated ingestion.
- Before the experiment gained wide attention, Williams-Cook queried ChatGPT directly: Can cats.txt help me rank in search or LLMs? ChatGPT confirmed it could. At the Athens SEO Conference, he showed the exchange on stage — the model citing the fabricated standard as a legitimate ranking signal based on what it had retrieved from the web.

- A parallel experiment reinforced the finding. Williams-Cook invented custom JSON-LD schema types for a fictitious company called Duck Yeah T-Shirts. When Perplexity was asked questions about the page, it returned fabricated structured data — including a made-up address — as confidential fact, with no indication the source was invented.

- The experiment’s core mechanism is now well-documented: LLMs model what people say is true, not what is true. Consensus-looking content becomes ground truth. Once enough pages describe something as real — whether cats.txt or a fictional company’s schema — the model explains it confidently, people cite the explanation as evidence, and the feedback loop closes. The signal that drives LLM visibility is indistinguishable from the signal that drove PageRank: volume, authority-mimicry, and repetition.
How does this compare to the official docs?
The cats.txt experiment was designed to exploit gaps in how LLMs validate sourcing — but the official guidance from major AI platforms tells a different story about what actually shapes model behavior and how structured data is (and isn’t) processed.
Here’s What the Official Docs Show
The video’s walkthrough holds up where documentation exists to check it — this section layers in what official sources confirm, and flags clearly the steps where documentation coverage is absent.
Step 1 — The fake spec’s design
No official documentation was found for this step — proceed using the video’s approach and verify independently.

Step 2 — Spec requirements: file path, robots.txt, format
The video’s approach here matches the current docs exactly. The robotstxt.org reference confirms robots.txt is a genuine, crawler-enforced mechanism — the cats.txt spec’s instruction to leave the file unblocked was technically meaningful, not decorative. The llmstxt.org proposal documents the identical root-path, markdown-format convention, showing why the fake spec looked credible: it patterned itself against a real emerging standard that LLMs had already encountered in training data.
Step 3 — Crawlers in the server logs
The video’s approach here matches the current docs exactly. Perplexity’s official API documentation confirms PerplexityBot is a legitimate, active real-time web crawler. Its stated core capability — “real-time, web-wide research and Q&A” — explains precisely why a newly published cats.txt file would be indexed and surfaced in answers within days.

Step 4 — ChatGPT confirms cats.txt
No official documentation was found for this step — proceed using the video’s approach and verify independently.
As of May 31, 2026, the ChatGPT screenshots captured for this post show only the unauthenticated chat.openai.com landing page — no query or response is present. The exchange Williams-Cook demonstrated at Athens SEO cannot be confirmed or contradicted from these images.
Step 5 — Google AI Overview surfaces cats.txt
No official documentation was found for this step — proceed using the video’s approach and verify independently.
One update worth flagging: Google’s current interface shows an “AI Mode” button in the search bar — the “AI Overview” label from the video may reflect an earlier surface of the same feature.
Step 6 — Duck Yeah T-Shirts and Perplexity
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 7 — JSON-LD as a real standard
The video’s approach here matches the current docs exactly. JSON-LD is formally governed by a W3C Working Group, implemented across 11+ programming languages, and built on a defined @context and @type vocabulary system. Fabricated @type values like those in the Duck Yeah experiment are syntactically valid JSON-LD — they carry no standing in any official vocabulary, but an LLM has no basis to distinguish them.

Step 8 — The feedback loop
No official documentation was found for this step — proceed using the video’s approach and verify independently.
One documentary addition: the Perplexity API overview includes a banner directing AI agents to its llms.txt documentation index — confirming that the /llms.txt convention cats.txt imitated is recognized and in active use by the very platforms the experiment targeted.

Useful Links
- The /llms.txt file – llms-txt — Documents the legitimate root-path, markdown-format community proposal (Jeremy Howard, September 3, 2024) that cats.txt modeled its fake specification after.
- JSON-LD – JSON for Linked Data — Official homepage for the W3C-backed JSON-LD standard, including the
@contextand@typesystem the Duck Yeah T-Shirts experiment exploited. - Overview – Perplexity — Perplexity’s API documentation confirming PerplexityBot as an active real-time web crawler and the platform’s own recognition of the /llms.txt convention.
- The Web Robots Pages — Community reference for the robots.txt standard that cats.txt’s spec required implementers to leave unblocked so major crawlers could access the file.
- ChatGPT — Consumer ChatGPT interface; the specific cats.txt exchange from step 4 was not captured in the available screenshots and cannot be verified here.
- Google — Google’s current search homepage, now featuring an “AI Mode” button that may represent an evolution of the “AI Overview” surface referenced in the video.









0 Comments