Stop Burning Tokens: How to Build an Outcome Maxing Framework
One developer spent $150,000 on AI tokens, and the company couldn’t explain what they got for it. Enterprise AI token spend grew 13x year-over-year across more than 50,000 businesses, but most teams have no framework for connecting usage to results. This tutorial walks you through the “outcome maxing” framework — a discipline that ties every token to a measurable business outcome. By the end, you’ll have a function-by-function outcome map, a two-question filter for every AI build, and a model-selection principle that stops budget bleed before it starts.
- Acknowledge the scope of the problem. Enterprise AI token spend grew 13x year-over-year according to Ramp data covering 50,000+ businesses. The issue isn’t the cost itself — it’s that most organizations can’t write a single sentence connecting that spend to a business outcome. If you can’t explain what changed in your business because of your AI investment, you’re running an expense, not a strategy.

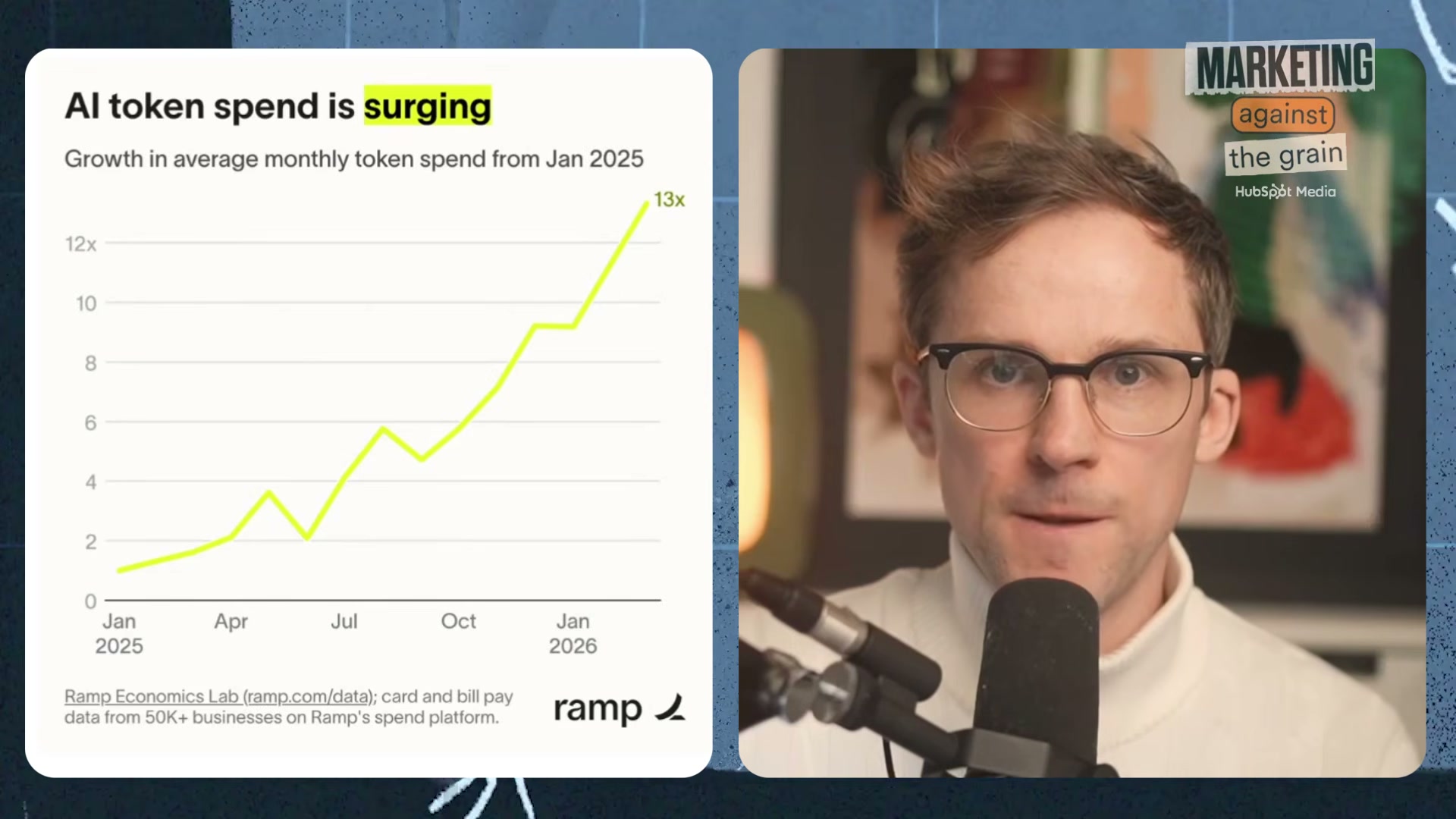
- Distinguish token maxing from outcome maxing. Token maxing is usage for its own sake — burning credits because the technology is available and the culture rewards it. Outcome maxing means every unit of AI spend maps to a measurable result: more deals closed, lower support ticket volume, faster content production. HubSpot CEO Yamini Rangan crystallized the distinction in a LinkedIn post that reframes AI spend as a strategic discipline rather than a badge of ambition.


- Apply the one-sentence test. Before approving any AI initiative, write one sentence describing the specific business outcome it achieves. If you can’t complete that sentence, the initiative is token maxing dressed as strategy. This test applies equally to individual builds, team-level pilots, and company-wide programs.
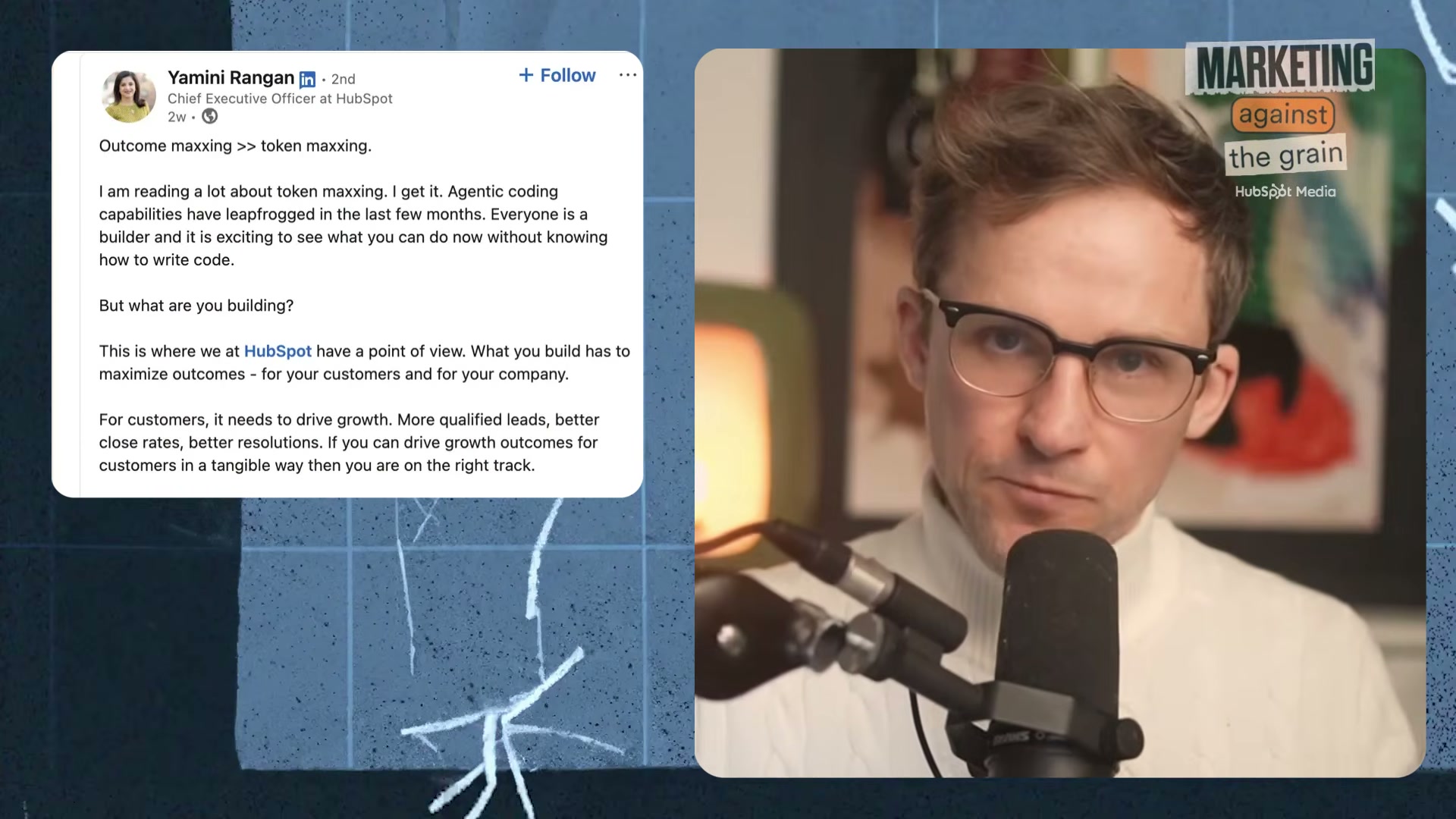 HubSpot CEO Yamini Rangan’s LinkedIn post that sparked the debate: ‘Outcome maxxing >> token maxxing.’
HubSpot CEO Yamini Rangan’s LinkedIn post that sparked the debate: ‘Outcome maxxing >> token maxxing.’
-
Set quarterly outcome targets before allocating AI budget. Define what each function is responsible for achieving before the quarter starts — not after the spend happens. A sprint-based operating model with discrete tasks tied to those targets keeps teams accountable and exposes activity metrics — tokens burned, prompts run, features shipped — for what they are: proxies, not outcomes.
-
Map outcomes by function. For sales, the signal is productivity per rep and deals closed. For support, it’s ticket deflection rate paired with a quality score that confirms the customer experience held. Marketing is harder to isolate: track content production speed, agency spend reduction, and engagement lift — not volume of content created.
-
Filter every AI build with two questions. Ask: (1) What is the single outcome this achieves? (2) Will this be used more than once? A build that fails either test is likely a distraction. One-off token burns rarely compound into business value, regardless of how sophisticated the underlying model is.
-
Match model selection to task complexity. Routine, well-defined tasks — formatting, summarization, classification — belong on cheap or open-source models. High-leverage work requiring reasoning, judgment, or nuanced output justifies a frontier model. Most enterprise users never make this distinction; they default to the best available model on every task and absorb the cost without realizing it.
-
Treat current token pricing as a learning window. Token costs are currently subsidized by venture capital — AI companies are running negative margins to acquire usage at scale. That pricing environment will not hold indefinitely. The time to build outcome-maxing discipline is now, while experimentation is cheap enough to absorb the cost of getting it wrong.
Warning: this step may differ from current official documentation — see the verified version below.
How does this compare to the official docs?
The framework here is strategically coherent, but it emerges from a single discussion — the next act tests these principles against what AI vendors and enterprise marketing platforms actually prescribe in their own documentation.
Here’s What the Official Docs Show
The video’s strategic framework holds up well — documentation fills in some specifics and flags a few places where the evidence doesn’t match exactly. What follows works through the same steps with what vendors actually publish.
Step 1 — The scope of the problem
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 2 — Token maxing vs. outcome maxing
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 3 — The one-sentence test
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 4 — Set quarterly targets before allocating budget
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 5 — Map outcomes by function
The video assigns ticket deflection as Support’s primary metric and agency spend reduction as Marketing’s primary metric. As of April 28, 2026, HubSpot’s Service Hub documentation surfaces customer health scores and retention — ticket deflection does not appear in their published outcome framing. HubSpot’s Marketing Hub describes outcomes as lead attraction, campaign personalization, and content tracking — agency spend displacement is not mentioned. Both are legitimate internal KPIs you can define and track; they just aren’t metrics HubSpot surfaces natively. Know that before you build your reporting stack against platform-native dashboards.
One structural note worth flagging: HubSpot now includes a dedicated AI layer called Breeze sitting alongside the Hubs. Any outcome measurement inside HubSpot should account for Breeze-specific activity as a distinct usage category — this didn’t exist in earlier versions of the platform.
Step 6 — The two-question filter
No official documentation was found for this step — proceed using the video’s approach and verify independently.

Step 7 — Match model to task complexity
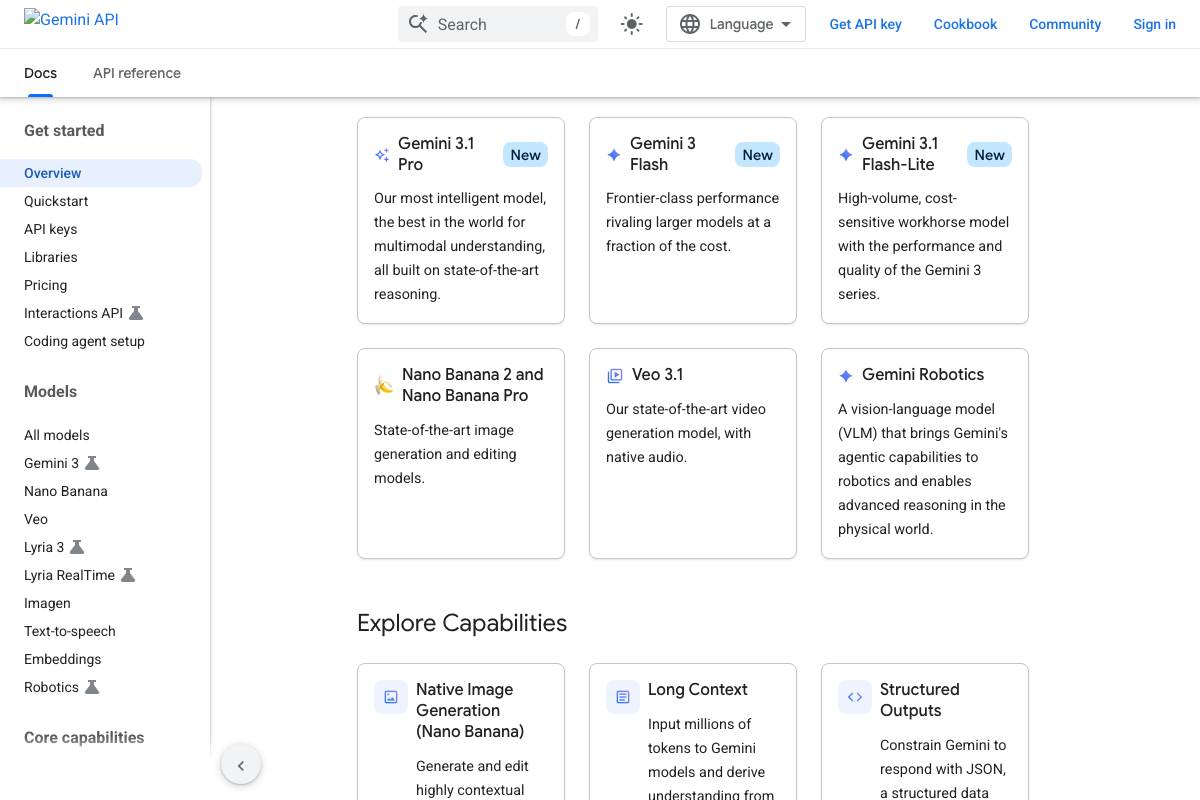
The video’s approach here matches the current docs exactly. Google’s Gemini API documentation explicitly labels Gemini 3.1 Pro as the flagship for high-complexity reasoning, Gemini 3 Flash as delivering “frontier-class performance rivaling larger models at a fraction of the cost,” and Gemini 3.1 Flash-Lite as a “high-volume, cost-sensitive workhorse” — a three-tier structure that maps directly to the video’s recommendation to stop defaulting to your most capable model on every task.
One extension the docs surface that the video doesn’t: even lower-cost Flash models currently carry a “preview” designation, which can affect pricing stability and SLA guarantees in production environments.
Step 8 — Treat current pricing as a learning window
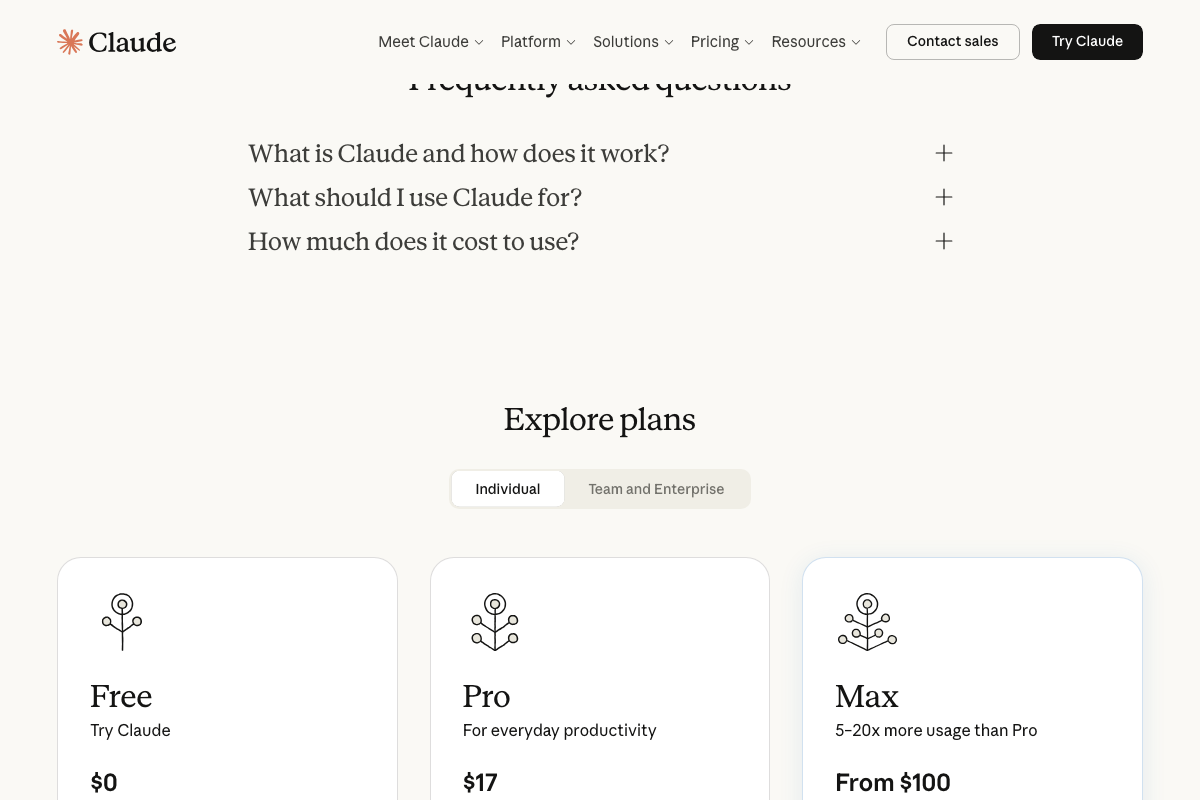
The “subsidized token pricing” claim is unverified by any official source reviewed here. The pricing visible in Claude’s documentation shows consumer subscription tiers — Free, Pro at $17/month, Max from $100/month — which are not the per-token API rates enterprise token spend is billed against. No vendor reviewed officially labels current API pricing as subsidized. The underlying strategic point still holds: build outcome discipline while experimentation is affordable, regardless of whether the subsidy framing is technically accurate.
Useful Links
- Gemini API | Google AI for Developers — Official Gemini API documentation including model family tiers, explicit cost-performance positioning, and a Python quickstart using the Flash preview model.
- HubSpot — HubSpot product homepage describing the Marketing, Sales, Service, and Content Hubs alongside the Breeze AI layer and Smart CRM architecture.
- Claude.ai — Claude’s consumer interface and subscription pricing page showing current Free, Pro, and Max plan tiers; note that API token pricing is documented separately at docs.anthropic.com.
- ChatGPT — OpenAI’s consumer ChatGPT interface; API platform documentation and token pricing are available separately at platform.openai.com/docs.
- Perplexity — Perplexity’s home interface showing a model selector and agentic Computer mode; API documentation is available separately at docs.perplexity.ai.
- GitHub — GitHub’s homepage featuring GitHub Copilot, which operates on seat-based subscription pricing rather than per-token API billing — a structural distinction the token-spend framework in this tutorial does not address.









0 Comments