Claude Mythos: What Anthropic’s Unreleased Flagship Model Means for Agentic AI
Anthropic has previewed Claude Mythos, a flagship model so capable the company won’t release it publicly — yet. Understanding the benchmark data, the security findings, and the competitive dynamics behind the announcement explains why this model marks a qualitative shift in agentic AI — and who stands to benefit most.
- Mythos is Anthropic’s new top-tier model, sitting above Opus in the lineup. Anthropic withheld public release in favor of Project Glass Wing: a pre-release security partnership designed to harden infrastructure before a model capable of autonomous exploit generation reaches the general public.
- SWE-bench Verified jumped from 80.8 on Opus 4.6 to 93.9 on Mythos Preview. Multimodal understanding went from 27.1% to 59%. USAMO reached 97.6% and GPQA Diamond hit 94.5%. These aren’t incremental improvements — the gap between Mythos and the current public frontier exceeds any prior generational step.

- Gemini 3.1 Pro scores 80.6 on SWE-bench; Opus 4.6 scores 80.8. Mythos at 93.9 doesn’t close the gap — it creates a new one. GPT-5.4 also trails across every agentic evaluation category in the comparison table.
- Project Glass Wing’s partner list covers the enterprise security stack: Microsoft, Google, AWS, NVIDIA, Palo Alto Networks, CrowdStrike, JPMorgan Chase, Cisco, Broadcom, the Linux Foundation, and Apple — each organization using Mythos to find vulnerabilities in their own infrastructure before the model ships publicly.

- In Firefox JavaScript shell exploitation trials, Mythos succeeded 72.4% of the time versus 14.4% for Opus 4.6 and 4.4% for Sonnet 4.6. It also identified a 27-year-old vulnerability in OpenBSD — long considered one of the most security-hardened operating systems available — and surfaced 181 Firefox vulnerabilities compared to the two found by the prior Opus model.

- GLM 5.1, an open-source model from Zhipu AI, launched roughly nine hours before the Mythos announcement, scoring 54.9 on SWE-bench Pro under a fully open Apache 2.0 license — near parity with Opus 4.6’s 57.5. Anthropic’s coordinated press release, co-signed by Microsoft, Google, and the Linux Foundation, did not arrive by coincidence.

-
The presenter’s central argument: early autonomous agent frameworks like BabyAGI and AgentGPT failed not because of architectural flaws in the code, but because GPT-3.5 and early GPT-4 couldn’t hold context or adhere to long instruction sets reliably. Opus 4.5 was the inflection point. Mythos extends that capability lead by a larger margin than any prior release.
-
The presenter maps industries on a spectrum from fully digital — coders, content creators — to fully physical trades where software leverage is minimal. Model improvements expand the range of industries where agentic tools become viable. Mythos moves the line again, and the direction of movement matters more than where it currently sits.
-
The OpenClaw OAuth ban forced users from a $200/month flat rate onto API credit consumption, pushing costs to $2,000–$3,000/month for heavy workflows. Mythos access — projected before end of April based on Polymarket odds — will add another pricing variable for teams building on the API.
-
Palo Alto Networks characterized the downstream security posture shift directly: “It’s clear that these models need to be in the hands of open source owners and defenders everywhere.” Competitor responses, new categories of agentic tooling, and accelerated vulnerability exposure are all downstream of Mythos shipping.

How does this compare to the official docs?
The benchmark figures, partner claims, and security findings covered here derive from Anthropic’s press preview as reported in the video — Act 2 goes directly to Anthropic’s primary documentation to verify what held up, what shifted in framing, and what the announcement left out entirely.
Here’s What the Official Docs Show
Act 1 laid out the video’s take on Claude Mythos — the benchmark claims, the security findings, and the competitive context. The documentation confirms the core story while adding several precision points that matter if you’re building strategy around these numbers.
Step 1 — Mythos as Anthropic’s top-tier unreleased model
The video’s approach here matches the current docs exactly. The API docs confirm Mythos Preview exists outside the standard model lineup. One clarification worth carrying forward: the official docs describe it as “a research preview model for defensive cybersecurity workflows” with invitation-only access and no self-serve sign-up — not a general-purpose flagship.
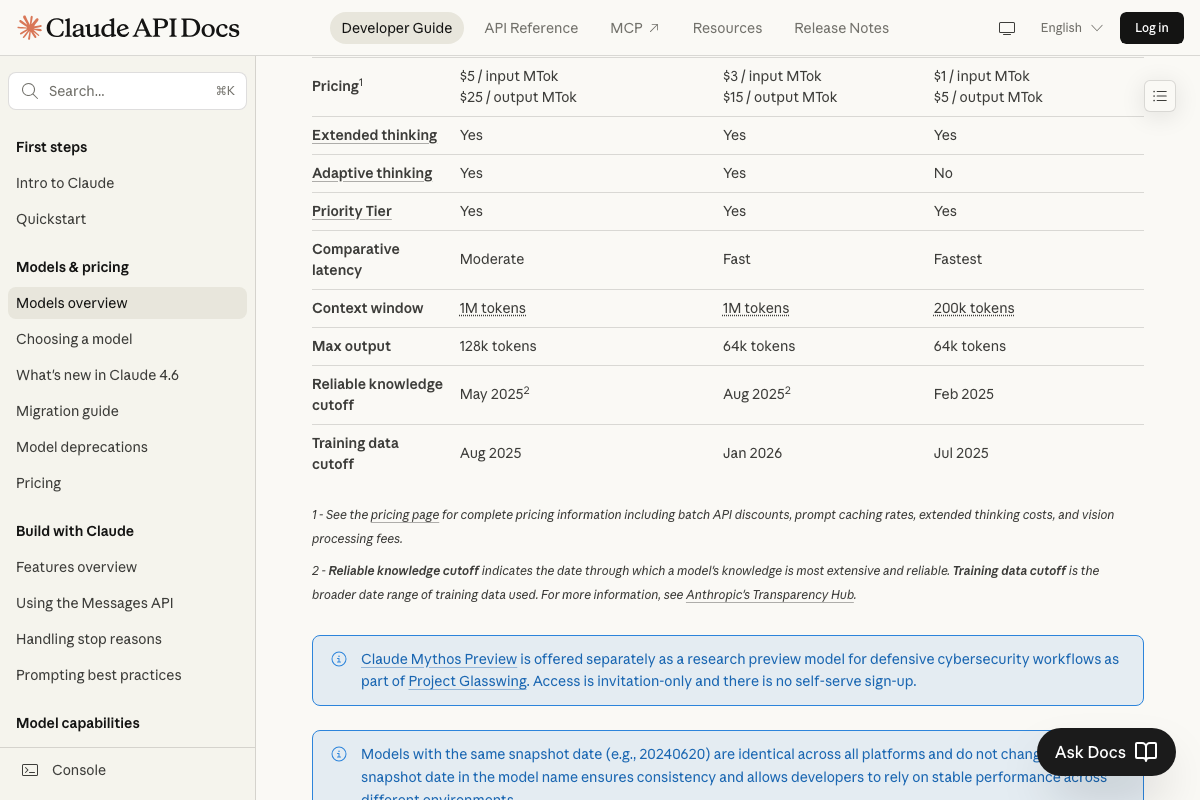
Step 2 — SWE-bench Verified benchmark scores
Claude Mythos does not appear on the public SWE-bench leaderboard, so the 93.9 and 59% Multimodal figures cannot be verified. As of April 8, 2026, the correct SWE-bench Verified score for Claude Opus 4.6 is 75.60 — the video states 80.8, which skews the improvement gap significantly.
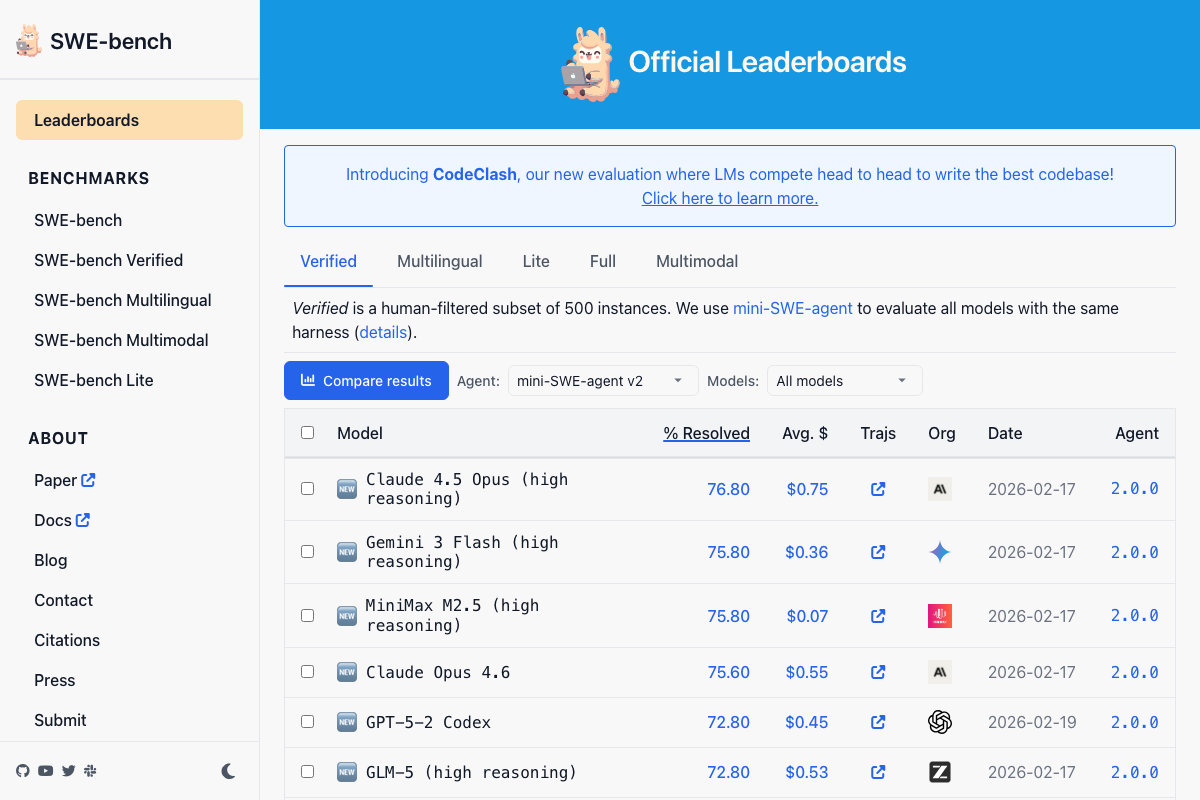
Step 3 — Competitive benchmarks: Gemini 3.1 Pro and GLM 5.1
No official documentation was found for this step — proceed using the video’s approach and verify independently.
As of April 8, 2026, no model named “Gemini 3.1 Pro” appears on the SWE-bench leaderboard or the DeepMind site — the only confirmed Gemini 3.1-generation product is Gemini 3.1 Flash Live. The closest leaderboard entry is “Gemini 3 Flash (high reasoning)” at 75.80, not 80.6. For the GLM entry, the leaderboard shows “GLM-5 (high reasoning)” at 72.80; the video cites “GLM 5.1” at 54.9 — both the model name and score differ.

Step 4 — Project Glasswing and the security partner consortium
The video’s approach here matches the current docs exactly. Both the Anthropic homepage and API docs confirm the partner initiative is real and Anthropic-branded. As of April 8, 2026, the correct spelling is “Glasswing” — one word — not “Glass Wing” as used in the video.
Step 5 — OpenBSD and Firefox vulnerability findings
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Neither the OpenBSD nor the Firefox homepages contain any reference to AI-discovered vulnerabilities, Project Glasswing, or Claude Mythos. The 27-year-old OpenBSD vulnerability and the count of 181 Firefox vulnerabilities cannot be confirmed from any available screenshot.

Step 6 — GLM competitive timing and open-source context
No official documentation was found for this step — proceed using the video’s approach and verify independently.

Steps 7–8 — Agentic framework history and industry spectrum
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 9 — Pricing and API access
No official documentation was found for this step — proceed using the video’s approach and verify independently.
As of April 8, 2026, the claude.ai Max subscription starts at $100/month — the video’s figure of $200/month does not correspond to any documented consumer subscription tier on the pricing page.
Step 10 — Palo Alto Networks and downstream implications
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Useful Links
- Home \ Anthropic — Anthropic’s homepage confirming Project Glasswing as an official, actively promoted initiative.
- Models overview – Claude API Docs — The only public Anthropic documentation referencing Claude Mythos Preview, including its invitation-only access restrictions and cybersecurity scope.
- SWE-bench Leaderboards — Public software engineering benchmark leaderboard used to cross-reference all model coding performance scores cited in the video.
- Google DeepMind — DeepMind’s homepage and news feed, checked for any Gemini 3.1 Pro model announcement or product card.
- OpenBSD — Official OpenBSD project homepage, checked for public disclosure of any AI-discovered vulnerability.
- Get Firefox for desktop and mobile — Firefox.com — Mozilla Firefox homepage, checked for any vulnerability count data attributed to Claude Mythos or Project Glasswing.
- Claude Code — Claude.ai consumer product page showing current subscription pricing tiers, including the Max plan starting point.









0 Comments