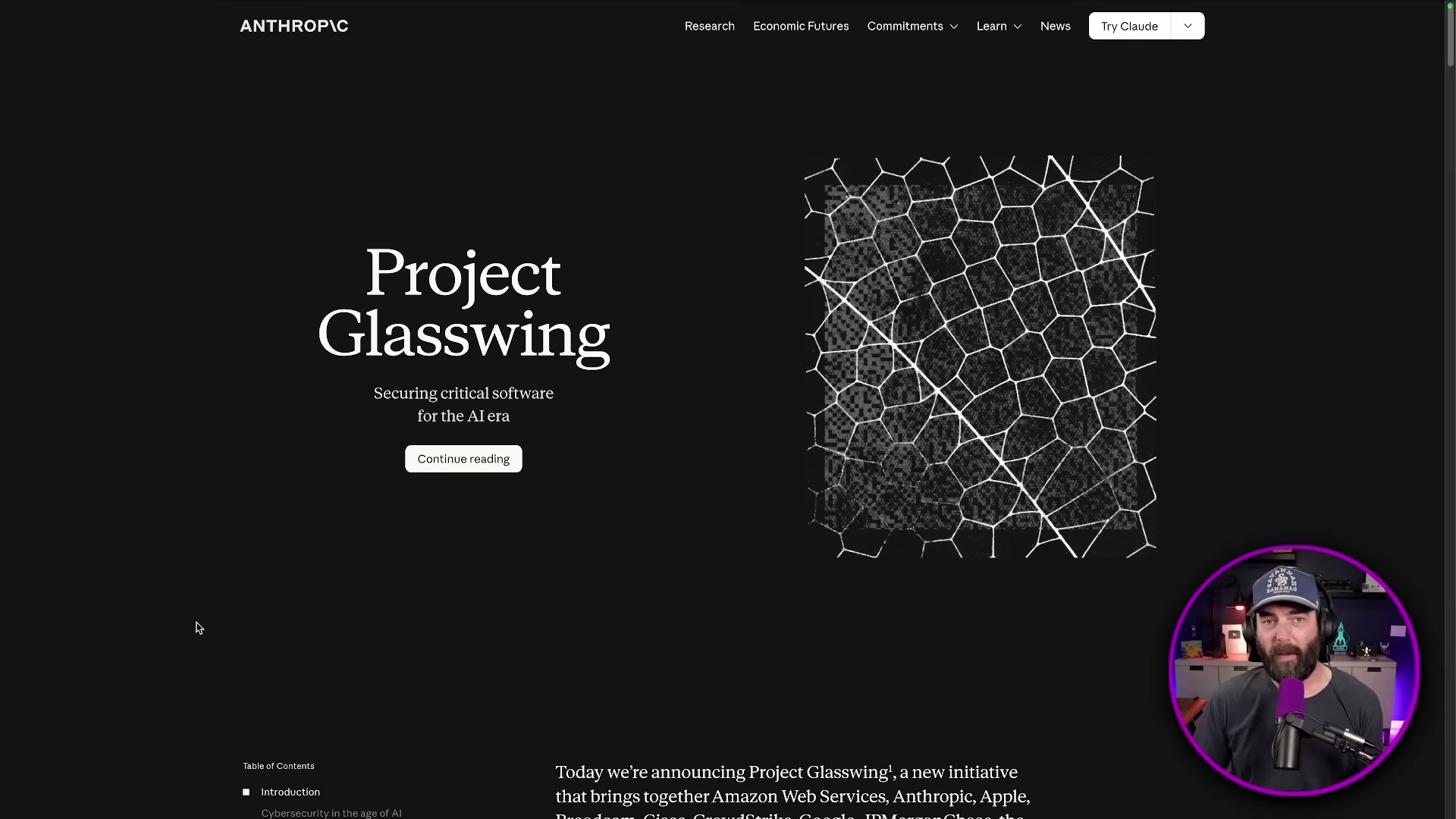
Claude Mythos, Project Glasswing, Meta Muse Spark, and GLM 5.1: This Week’s AI Releases
Three stories defined AI news this week: Anthropic’s decision to withhold its most capable model from public release, Meta’s first output from its new Super Intelligence Labs, and an open-source release from ZAI that’s flying under the radar. After working through this breakdown, you’ll understand what Claude Mythos actually is, why it isn’t available to you, where to access Muse Spark right now, and why GLM 5.1 deserves a closer look than the coverage suggests.
-
Anthropic describes Claude Mythos as a general-purpose unreleased frontier model whose coding capabilities surpass all but the most skilled human security researchers. Mythos Preview has already identified thousands of high-severity vulnerabilities across major operating systems and web browsers — including a 27-year-old flaw in OpenBSD and a 16-year-old vulnerability in FFmpeg. Anthropic concluded that the risk of general release outweighs the benefits, citing both defensive and offensive potential the model has demonstrated.
-
The accompanying 245-page system card benchmarks Mythos against Opus 4.6 and other frontier models. On CyberGym’s cybersecurity vulnerability reproduction task, Mythos Preview scores 83.1% versus Opus 4.6’s 66.6%. The lead widens across software engineering evaluations: SWE-bench Verified (93.9% vs. 80.8%), SWE-bench Multimodal (59.0% vs. 27.1%), SWE-bench Multilingual (87.3% vs. 77.8%), and Terminal-Bench 2.0 (82.0% vs. 65.4%).
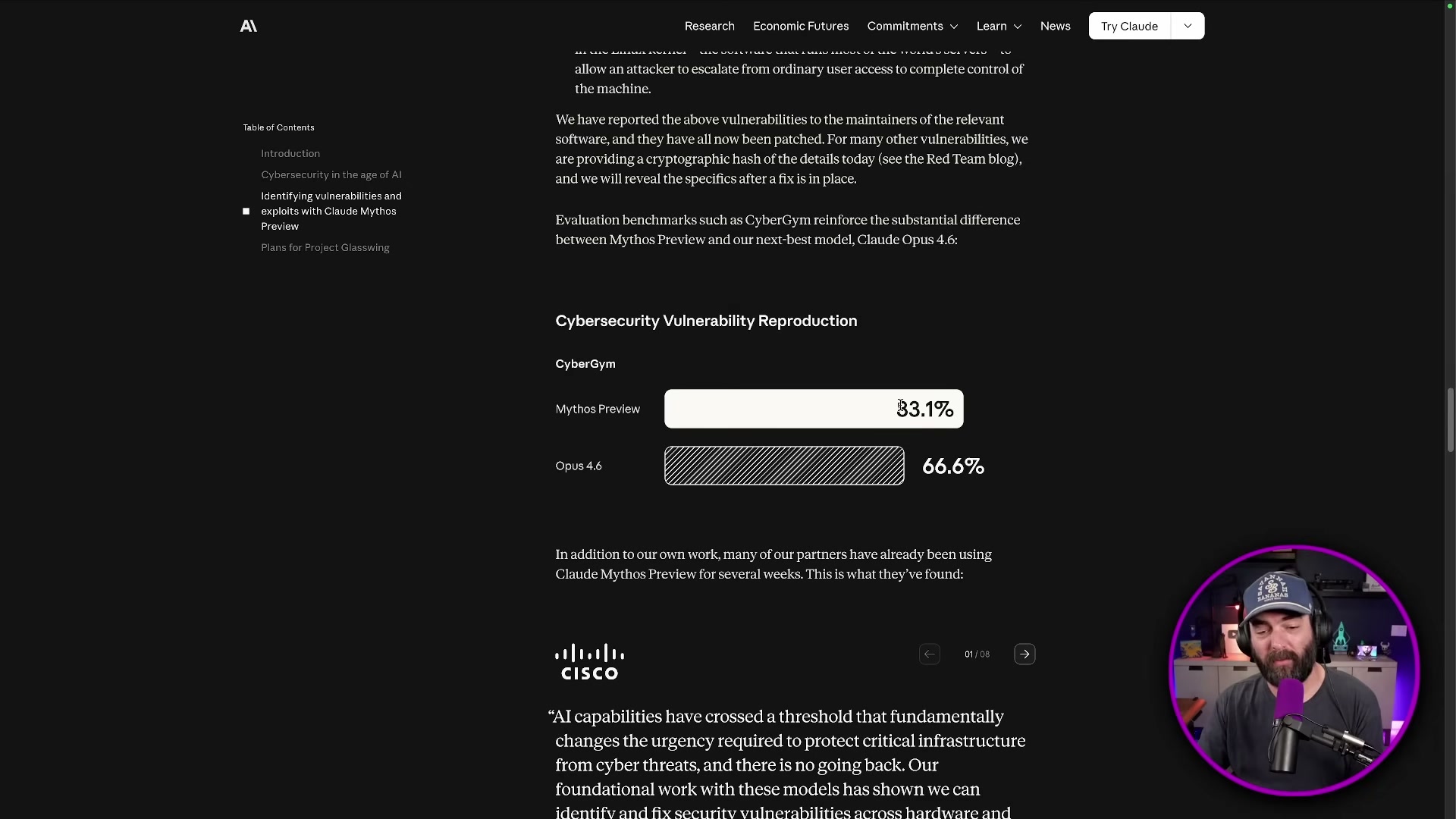

- Rather than a general release, Anthropic launched Project Glasswing — a controlled-access program routing Mythos Preview to cybersecurity specialists at 12 founding organizations: AWS, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. The rationale: equivalent capabilities will proliferate regardless of what any single lab does, so getting defenders out ahead of the vulnerabilities is the more responsible path.

- The “too dangerous to release” framing has precedent. In February 2019, OpenAI announced GPT-2 with a staged rollout and triggered headlines calling it a “weapons-grade chatbot.” The gap between that panic and GPT-2’s actual impact collapsed within months. The cybersecurity threat Anthropic identifies for Mythos is more specific and technically grounded than the 2019 disinformation argument — but the rhetorical pattern is worth holding in mind as you evaluate the claims.
-
Meta’s Muse Spark is the first model out of Meta Super Intelligence Labs, assembled after Yann LeCun’s departure with Alexander Wang and engineers recruited from across the frontier AI industry. Unlike the Llama series, Muse Spark is closed-source — a notable shift in Meta’s stated position on model openness.
-
Benchmarked against Opus 4.6, Gemini 3.1 Pro, GPT 5.4, and Grok 4.2 Reasoning, Muse Spark leads the field on multimodal figure understanding and sits mid-pack for most coding and reasoning categories. A token efficiency comparison positions it as more cost-effective than GPT 5.4 and Claude 4.6, which makes it worth evaluating for high-volume production workloads even where it doesn’t top raw benchmark scores.
-
Access Muse Spark today through Meta AI. A private API preview is forthcoming — no confirmed date was available at time of recording.
Warning: this step may differ from current official documentation — see the verified version below.
-
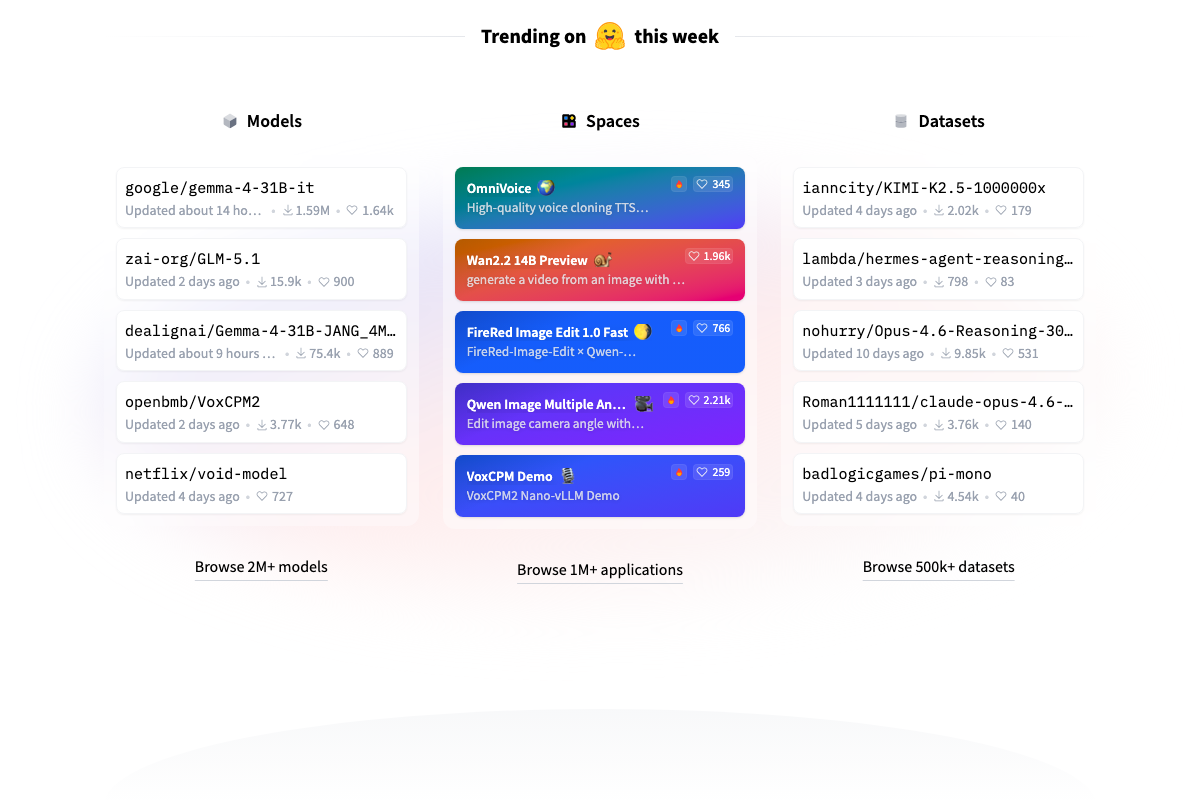
ZAI’s GLM 5.1 is an MIT-licensed model published to HuggingFace. The licensing makes it commercially deployable without the restrictions that come with most frontier models, which is the practical differentiator the benchmarks alone don’t capture.
-
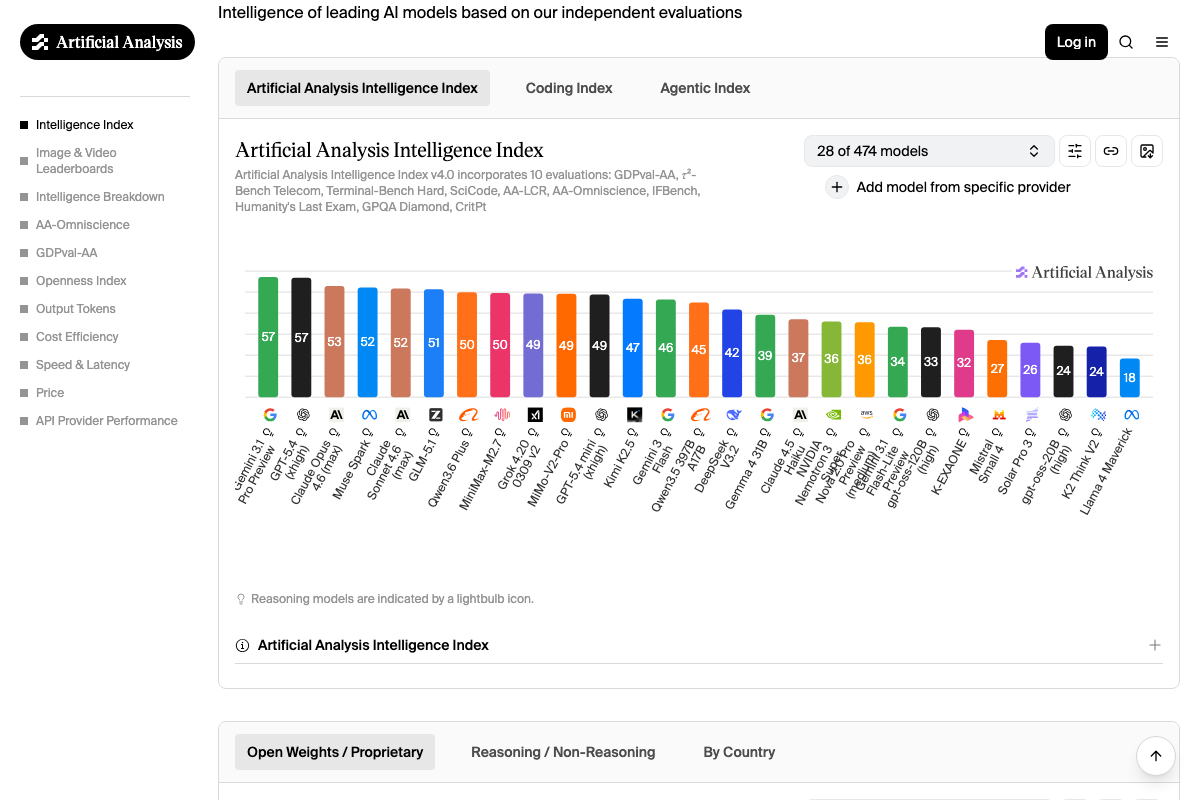
On SWEBench Pro coding benchmarks, GLM 5.1 competes directly with GPT 5.4, Opus 4.6, and Gemini 3.1 — though the video’s analysis ended before the full comparison was complete.
How does this compare to the official docs?
The video draws directly from Anthropic’s published Glasswing page and Meta’s benchmark disclosures, but the access paths, licensing terms, and benchmark methodologies all warrant a closer read against primary sources before you make deployment decisions.
Here’s What the Official Docs Show
Act 1 gave you the video’s take on this week’s major AI releases — and it got the big picture right on most stories. What follows fills in the naming precision, benchmark caveats, and a few unconfirmed claims that matter before you act on any of this.
Step 1 — Claude Mythos: the unreleased frontier model
No official documentation was found for this step — proceed using the video’s approach and verify independently.
No model named “Claude Mythos” appears on Anthropic’s public homepage, model listings, or any captured resource page. The most prominently featured model on Anthropic’s site as of April 10, 2026 is Claude Opus 4.6, described as “the world’s most powerful model for coding, agents, and professional work.”
Step 2 — The 245-page system card and benchmark data
No official documentation was found for this step — proceed using the video’s approach and verify independently.
As of April 10, 2026, no system card, safety report, or benchmark documentation for a model called Claude Mythos is linked or referenced anywhere on Anthropic’s public-facing pages. The benchmark figures cited in the video — CyberGym, SWE-bench Verified, Terminal-Bench 2.0 — cannot be confirmed from official sources captured here. Anthropic’s publicly available safety documentation includes the Responsible Scaling Policy and Claude’s Constitution; neither references Mythos.

Step 3 — Project Glasswing and the founding coalition
The video’s approach here matches the current docs on substance — Anthropic does operate a controlled-access cybersecurity program with the coalition described, and the honeycomb-mesh visual from the video appears on the official homepage.
One spelling correction worth making for any written reference: as of April 10, 2026, the correct name is Project Glasswing — one word, no space between “Glass” and “wing.” The video uses “Project Glass Wing” (two words), which reflects a misread of the official branding.
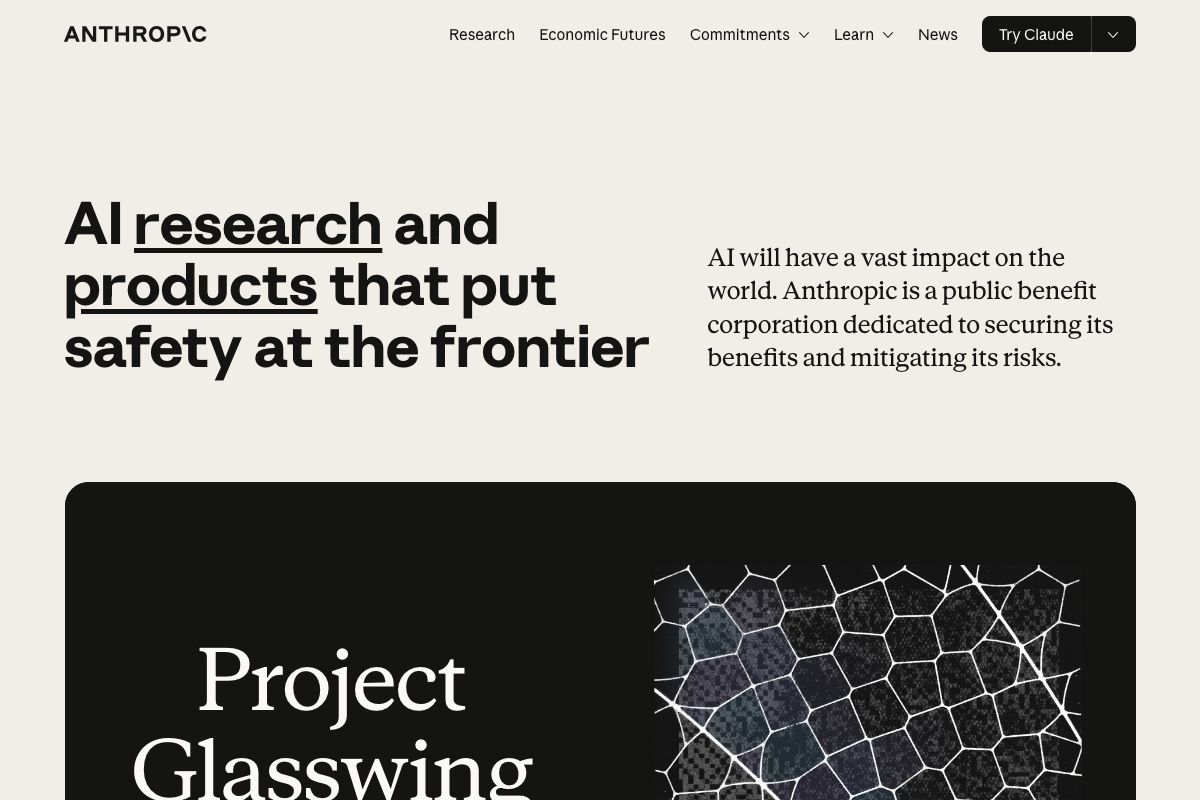
Step 4 — The GPT-2 “too dangerous to release” historical parallel
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 5 — Muse Spark and Meta Superintelligence Labs
The video’s approach here matches the current docs exactly on the core claim: Muse Spark is confirmed as the first model from this lab, and the ai.meta.com page describes it as “the first in a new series of models” in a featured section dated April 8, 2026.
One naming precision to carry forward: the organization is officially Meta Superintelligence Labs — “Superintelligence” is one compound word. The video’s “Meta Super Intelligence Labs” splits it across three words, which differs from the official branding used consistently across ai.meta.com.
Step 6 — Muse Spark benchmark comparisons
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Two points worth flagging before you cite the benchmark comparisons from this step. First, Muse Spark’s appearance on Artificial Analysis (confirmed via the April 9, 2026 changelog) is the closest independent verification available — but no specific benchmark table is legible from the captured screenshots. Second, the video compares Muse Spark against a model called “Grock 4.2.” As of April 10, 2026, no model with that name or spelling appears on the Artificial Analysis leaderboard. The xAI model is standardly spelled Grok — the “ck” spelling does not appear in any official source captured here.

Step 7 — Token efficiency and cost comparison
No official documentation was found for this step — proceed using the video’s approach and verify independently.
The Artificial Analysis homepage does confirm that an independent price-per-million-token benchmark infrastructure exists, and the cost range visible across the captured charts spans $0.30 to $10.00 per 1M tokens. The specific token efficiency positioning for Muse Spark relative to GPT 5.4 and Claude 4.6 described in the video cannot be confirmed from the available screenshots.
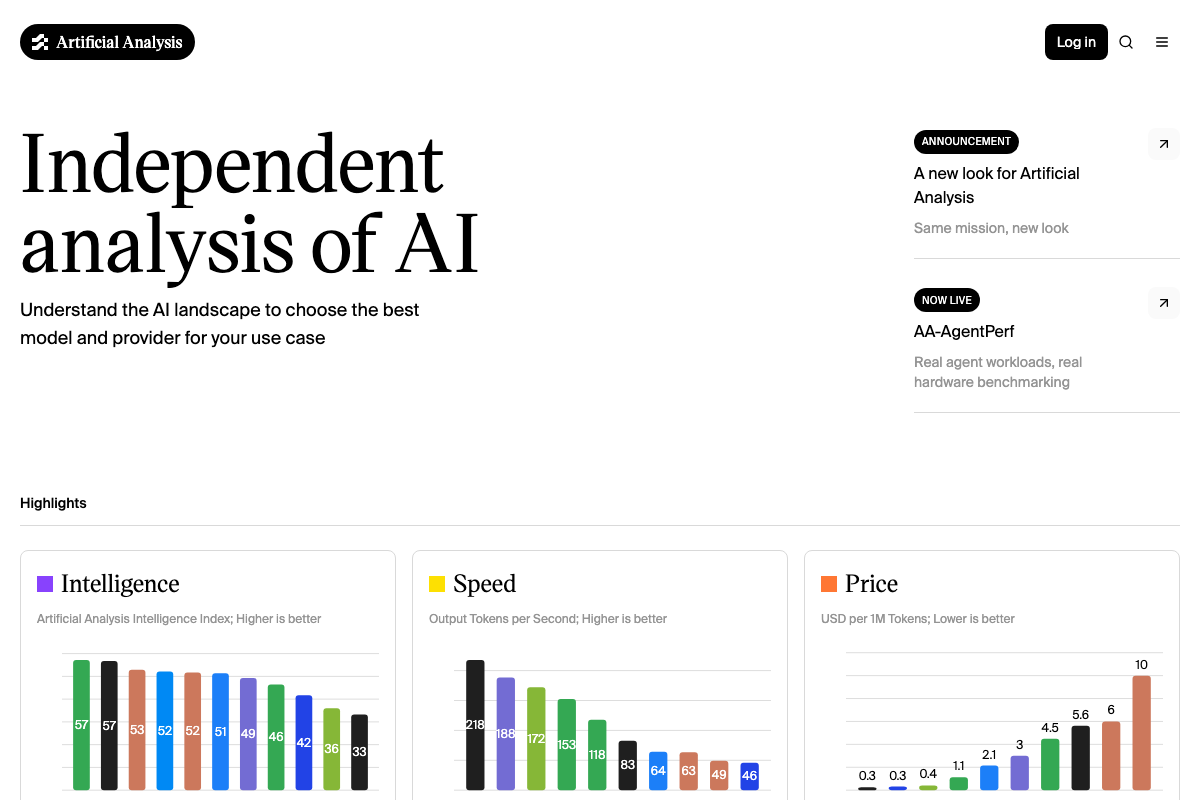
Step 8 — Accessing Muse Spark via Meta AI
The video’s approach here matches the current docs exactly: a “Try on Meta AI” button is visible directly alongside the Muse Spark entry on ai.meta.com, confirming access through the Meta AI interface.
One gap to note: no private API preview signup, waitlist, or developer access program for Muse Spark is visible on any Meta AI page captured. The “forthcoming private API preview” described in the video cannot be confirmed from official sources as of April 10, 2026.
Step 9 — GLM 5.1 on HuggingFace
The video’s approach here matches the current docs exactly. HuggingFace confirms zai-org/GLM-5.1 is publicly hosted under the ZAI organization namespace, ranked as the second-trending model site-wide at time of capture with approximately 15,900 downloads — consistent with the video’s framing of it as a newly released, commercially relevant open-source model.
Step 10 — GLM 5.1 on SWEBench and coding benchmarks
No official documentation was found for this step — proceed using the video’s approach and verify independently.
One important caveat from Artificial Analysis: the platform explicitly evaluates GLM-5.1 (Non-reasoning) — a qualifier the video does not mention. If the SWEBench Pro comparisons in the video were drawn from this evaluation, they apply to the non-reasoning variant only. Benchmark scores for non-reasoning models are not directly comparable to reasoning-enabled model scores without that distinction. Additionally, any comparison against “Grock 4.2” carries the same spelling and sourcing uncertainty noted in Step 6.
Useful Links
- Home \ Anthropic — Anthropic’s official homepage, featuring the Project Glasswing announcement and the Claude Opus 4.6 model listing as the most recently published public release.
- AI at Meta: Meta AI Products, Models and Research | AI at Meta — Meta’s AI hub confirming the Muse Spark announcement from Meta Superintelligence Labs, dated April 8, 2026, with direct access via the Meta AI interface.
- Hugging Face – The AI community building the future. — HuggingFace platform hosting
zai-org/GLM-5.1in the public model repository, confirming ZAI attribution and trending status at time of capture. - AI Model & API Providers Analysis | Artificial Analysis — Independent benchmarking platform tracking Intelligence, Speed, and Price metrics, with April 9, 2026 changelog entries confirming both Muse Spark and GLM-5.1 (Non-reasoning) evaluations.









0 Comments