What’s New in Claude Opus 4.7: Benchmarks, Vision, and Claude Code Upgrades
Anthropic’s Opus 4.7 release introduces meaningful jumps across coding benchmarks, document reasoning, and vision — alongside Claude Code workflow changes that will directly affect your token budget. This walkthrough covers every upgrade the release notes buried, including the new effort tier, the /ultra review command, and a tokenizer change that could quietly trip up existing automations.
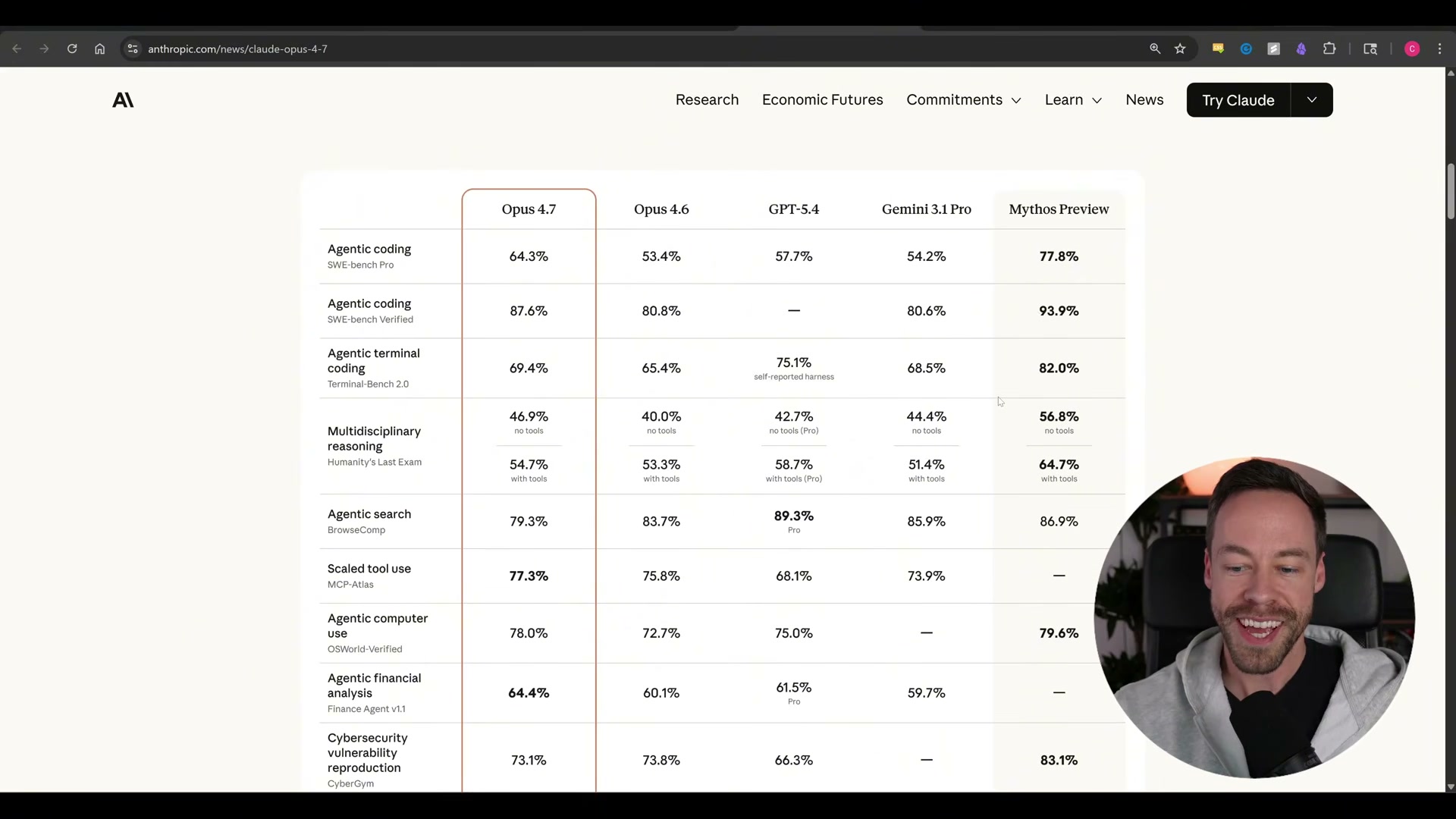
- Pull up the Anthropic benchmark comparison page and review Opus 4.7’s scores against Opus 4.6, GPT-5.4, and Gemini 3.1 Pro. On the three primary agentic coding tests — SWE-bench Pro, SWE-bench Verified, and Terminal Bench 2.0 — Opus 4.7 jumps from 53→64, 80→87, and 65→69 respectively. The only categories where another model leads are Agentic Search and Graduate-Level Reasoning, both claimed by GPT-5.4.
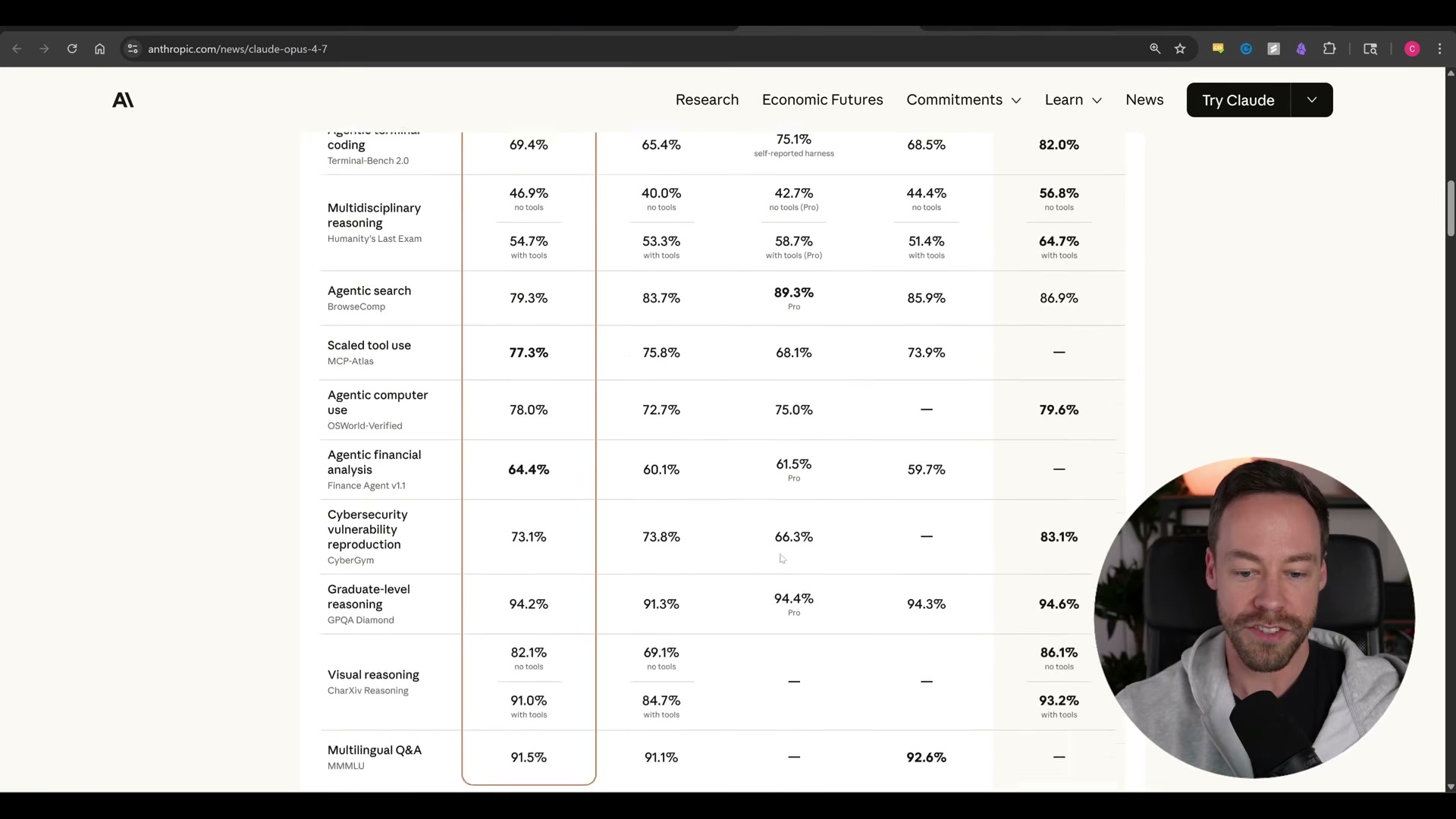
- Scroll down to the extended benchmark table to see visual reasoning climb from 69 to 82. Anthropic attributes this directly to a 3× resolution increase for image inputs — a meaningful change for any workflow involving diagrams, screenshots, or documents with embedded visuals.
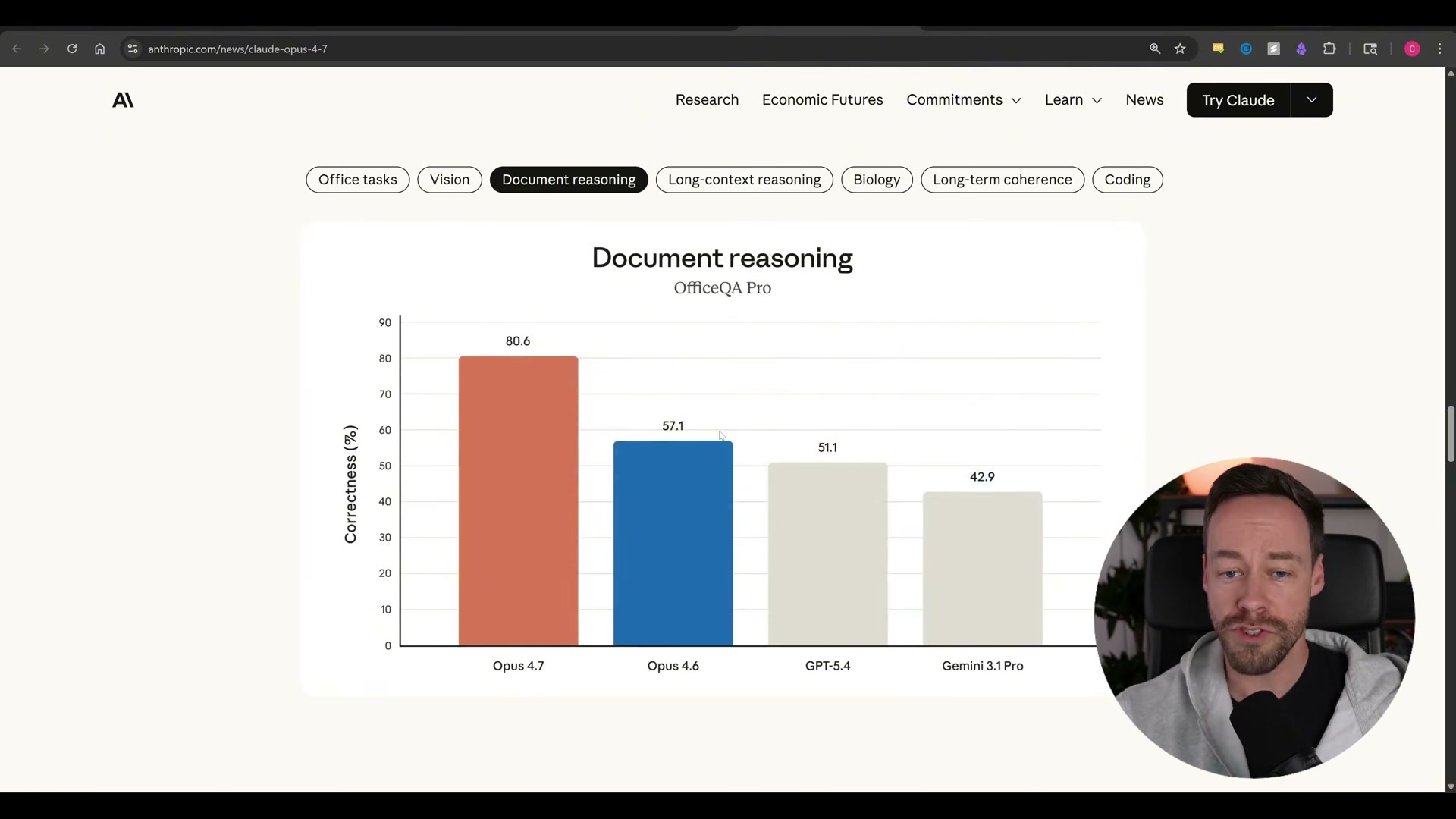
- Navigate to the Document Reasoning section of the benchmark charts. Opus 4.7 scores 80.6 on OfficeQA Pro against Opus 4.6’s 57.1 — a 41% improvement. For teams running document-heavy pipelines (contract review, knowledge work, office automation), this is the headline number.
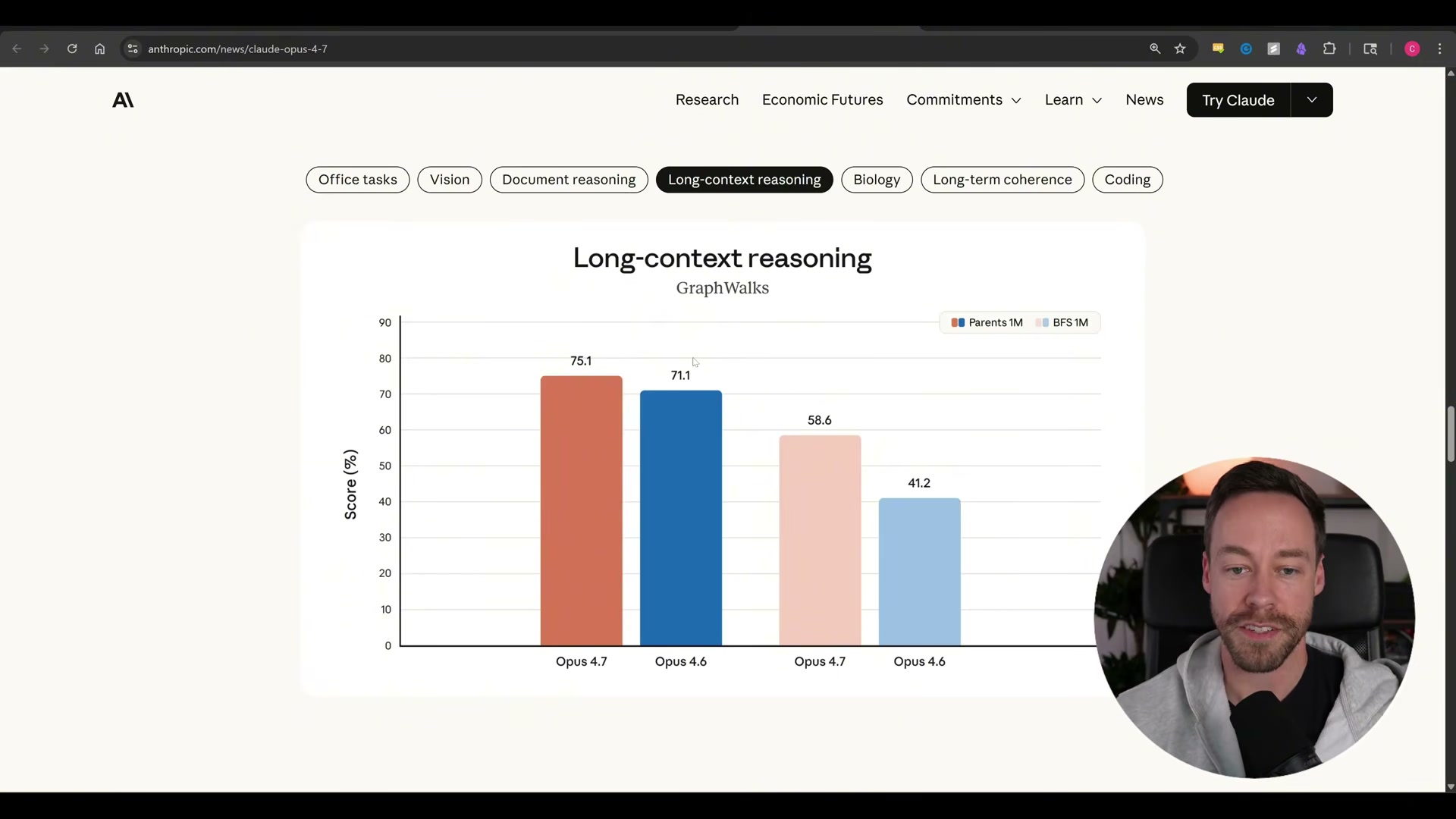
- Review the GraphWalks long-context reasoning results. Opus 4.7 reaches 75.1 on Parents 1M (up from 71.1) and 58.6 on BFS 1M (up from 41.2). The improvement is real, but context hygiene — clearing sessions at 20–25% of the context window — remains best practice.
-
Read the “Also launching today” section of the release page. Anthropic introduces
xhighas a new effort tier sitting betweenhighandmax. Claude Code now defaults toxhigh; the previous default wasmedium. To change effort level manually, run/effortfollowed by your target level inside a Claude Code session. -
Run
/ultra reviewin Claude Code to open a dedicated review session. This command gives the model a focused pass over existing work rather than folding review into an ongoing task context. -
Note that extended auto mode is now available as the recommended alternative to the
--dangerously-skip-permissionsflag.
Warning: this step may differ from current official documentation — see the verified version below.
- Check the migration section before upgrading any production workflow. Opus 4.7’s updated tokenizer maps the same input to 1.0–1.35× more tokens depending on content type. Combined with the
xhighdefault effort (which also increases output token usage), teams already near usage limits on Opus 4.6 atmediumeffort should audit their consumption before switching. Extended thinking has been removed in this release — Anthropic’s migration documentation covers the transition in detail.
How does this compare to the official docs?
The video covers the release accurately at a high level, but several details — particularly around effort level behavior, the task budgets API beta, and the extended thinking removal — are worth cross-referencing against Anthropic’s official migration documentation before you make any production changes.
Here’s What the Official Docs Show
The video’s walkthrough gives you a solid orientation to what’s new in Claude Opus 4.7 — this section layers in what the public documentation and official leaderboards actually show at time of writing, filling in where source data was unavailable to the creator. Where the official record differs from specific claims, those differences are called out plainly so you can calibrate before touching any production workflow.
Step 1 — Benchmark scores and model naming
The Anthropic homepage confirms Claude Opus 4.7 is a current release, described officially as improved for “coding, agents, vision, and complex professional work.” That framing aligns with the tutorial’s general direction.
However, the specific benchmark claims warrant a closer look at the primary source. As of April 16, 2026, the SWE-bench official leaderboard at swebench.com lists five benchmark variants: Verified, Full, Lite, Multilingual, and Multimodal. There is no variant labeled “SWE-bench Pro” — the tutorial’s reference to that name does not correspond to any category on the official leaderboard.
“Terminal Bench 2.0” likewise does not appear anywhere on swebench.com or in any associated documentation captured at time of writing.
Additionally, no entry labeled “Claude Opus 4.7” appears in the visible SWE-bench Verified leaderboard rows. The top Anthropic entry as of the screenshot date is “Claude 4.5 Opus (high reasoning)” at 76.80%, followed by “Claude Opus 4.6” at 75.60%. The score attribution and model naming in the tutorial should be treated as unconfirmed until Anthropic’s own benchmark page is consulted directly.
Steps 2–4 — Vision resolution, document reasoning, long-context results
No official documentation was found for these steps — proceed using the video’s approach and verify independently.
Steps 5–9 — X-High effort level, Claude Code defaults, /effort command, /ultra review, extended auto mode
The claude.ai/code URL resolves to a sign-in and pricing page, not feature documentation. Claude Code is confirmed as a Pro-tier feature ($17/month billed annually), but no effort level settings, slash command references, or default configuration details appear at this URL.
No official documentation was found for these steps — proceed using the video’s approach and verify independently.
Steps 10–11 — Token consumption impact and extended thinking migration
“Extended thinking for complex work” appears as a listed feature in the Free-tier plan on the claude.ai pricing page, but this refers to the consumer product surface — not the API-level parameter the tutorial’s migration step addresses.
No official documentation was found for the tokenizer change ratios, extended thinking removal, or migration documentation — proceed using the video’s approach and verify independently at docs.anthropic.com.
Useful Links
- Home \ Anthropic — Official Anthropic homepage confirming Claude Opus 4.7 as a current release with vision, coding, and agentic improvements highlighted.
- Claude Code — Entry point for Claude Code access; pricing, plan tiers, and subscription details available here; feature documentation lives at docs.anthropic.com/en/docs/claude-code.
- SWE-bench Leaderboards — Official SWE-bench leaderboard covering five benchmark variants (Verified, Full, Lite, Multilingual, Multimodal) with live model rankings and benchmark methodology descriptions.









0 Comments