Why Your CLAUDE.md File Is Degrading Claude Code Performance
A 2025 ETH Zurich study tested context files across multiple coding agents and benchmarks and reached a clear verdict: CLAUDE.md files make agents less effective and inflate inference costs by more than 20%. By the end of this walkthrough, you’ll understand what the research found, identify the one scenario where a context file genuinely helps, and know whether to delete yours.
- A
CLAUDE.mdfile is a Markdown instruction file that functions as a persistent system prompt. Every time you run Claude Code inside a project containing one, that file gets prepended to your prompt invisibly — on every single invocation. It’s where developers encode conventions: indentation preferences, pre-commit test commands, project-wide naming patterns.
- The
/initslash command is the standard auto-generation path. Run it inside a project and Claude Code traverses your entire architecture and produces aCLAUDE.mdautomatically. It’s a convenient on-ramp — and, as the research shows, often the wrong one. - The ETH Zurich paper Evaluating agents.md (arXiv:2602.11988) is the evidentiary foundation for this critique. Researchers benchmarked coding agents against 60,000+ open-source repositories to measure the actual effect of context files on task success rates and inference cost.

- The paper identifies four compounding failure modes. Context files don’t provide effective overviews — agents required as many or more steps to locate correct files even when given a codebase map. The documentation is also redundant: Claude Code traverses the codebase independently on every task, so a
CLAUDE.mddescribing its structure adds noise, not signal.

- The third and fourth problems are structural. Context files cause excessive tool-calling because agents follow
CLAUDE.mdinstructions closely — treating them as system prompts — and end up reading, searching, and writing more files than the task requires. Even conventions irrelevant to your current prompt get processed on every call. And crucially, stronger models don’t produce better context files: the degradation is architectural, not a content quality problem that better writing or a smarter model can fix.


- The practical recommendation: if you lack the technical depth to write a strictly minimal
CLAUDE.md— one containing only what Claude Code genuinely cannot infer by traversing the codebase itself — deleting it entirely produces a better outcome than leaving a/init-generated file in place. - There is one documented exception. In repositories that are large and contain zero existing documentation — no README, no example folders, no inline comments — LLM-generated context files improved performance by approximately 2.7% on average and outperformed developer-written documentation.
- That exception maps directly to personal assistant projects structured like Obsidian vaults. These are wide, flat repositories of Markdown files with no code architecture, no conventional project structure, and no reference material for Claude Code to orient from. A vault where Claude Code is the primary interface is the right home for a
CLAUDE.md— and the conventions worth writing there relate to communication style and personal workflow, not file architecture, which is exactly what/initwouldn’t produce.
- Anthropic recently updated
/initas an experimental, interactive multi-phase flow intended to produce more minimal output and steer users toward skills and hooks rather than bloated context files. Skills handle task-specific behaviors; hooks handle trigger-based automation. Neither requires adding instructions toCLAUDE.mdthat will be re-read on every prompt.
Warning: this step may differ from current official documentation — see the verified version below.
- The principle across all of this: standard coding projects are better served by no
CLAUDE.md, or by one written with enough technical precision to keep it ruthlessly minimal. Context files earn their place only at the margins — and defaulting to/initputs you on the wrong side of that line.
How does this compare to the official docs?
Anthropic’s own documentation approaches CLAUDE.md setup from a different angle — and Act 2 examines exactly where those recommendations align with the ETH Zurich findings and where they quietly diverge.
Here’s What the Official Docs Show
Act 1 builds a research-backed case against overloading CLAUDE.md — the official documentation supports that argument while adding a few details that sharpen the picture. What follows covers the same ground with doc evidence attached.
Step 1: CLAUDE.md as persistent context
The video’s approach here matches the current docs exactly. Two clarifications worth noting: the official documentation consistently capitalizes the filename as CLAUDE.md, and the load behavior is described as “at the start of every session” — not prepended to every individual prompt within a session. That distinction matters for understanding the actual cost model.

The docs also document a second persistence mechanism the tutorial doesn’t address: auto memory — Claude-authored notes capped at 200 lines per working tree. The tutorial’s cost analysis is specific to CLAUDE.md; auto memory’s built-in cap limits its overhead.
Step 2: The /init command
No official documentation was found for this step — proceed using the video’s approach and verify independently.

Steps 3–9: ETH Zurich research findings
No official documentation was found for this step — proceed using the video’s approach and verify independently.
The official docs do provide one indirect data point: the --bare CLI flag explicitly skips CLAUDE.md loading (along with hooks, skills, and MCP setup) for faster scripted calls — confirming that CLAUDE.md loading is a recognized, skippable cost.
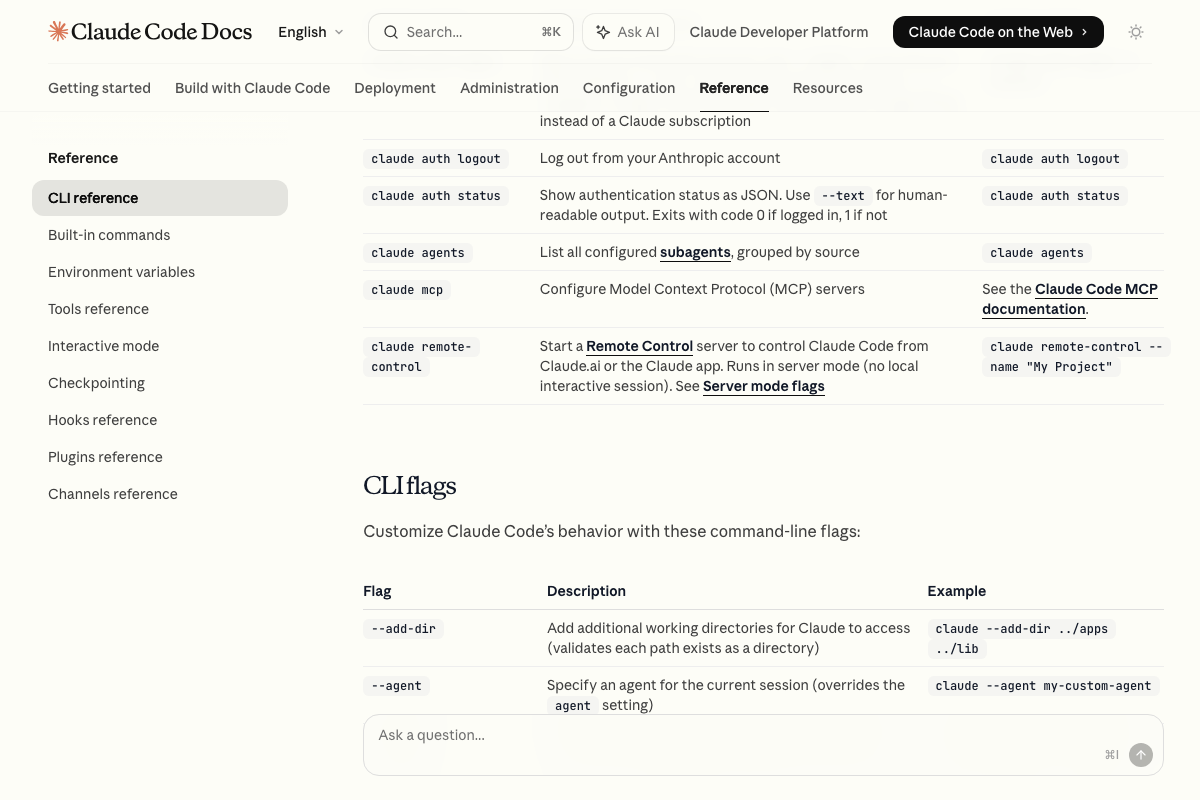
The docs also clarify that CLAUDE.md files in subdirectories load on demand, not at session start — partially mitigating the always-on token cost the tutorial attributes to CLAUDE.md broadly.
Step 10: The Obsidian vault exception
The video’s approach here matches the current docs exactly.
Step 11: Communication-style conventions for vaults
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Steps 12–13: /init redesign, skills, and hooks
The /init redesign described in Step 12 cannot be confirmed — the command does not appear in any of the three captured CLI reference pages. For skills and hooks, the video’s approach here matches the current docs exactly. One addition the tutorial doesn’t surface: skills stored in ~/.claude/skills/ are available across all your projects, not just the current one. CLAUDE.md is project-scoped; a personal skill travels with you.

Step 14: Keep CLAUDE.md minimal
No official documentation was found for this step — proceed using the video’s approach and verify independently.
The docs do note that large projects can break instructions into topic-specific subdirectory rules files — the documented path to keeping your session-start context lean without abandoning persistent instructions entirely.
Useful Links
- How Claude remembers your project – Claude Code Docs — Covers CLAUDE.md files, auto memory, and memory scoping options across project, user, and org levels
- CLI reference – Claude Code Docs — Full reference for Claude Code CLI commands and flags, including the
--bareperformance flag that explicitly skips CLAUDE.md - Extend Claude with skills – Claude Code Docs — Documentation on creating globally available, contextually loaded skills as an alternative to CLAUDE.md bloat
- Hooks reference – Claude Code Docs — Reference for nine distinct lifecycle hook events including blockable PreToolUse and UserPromptSubmit interception
- Obsidian – Sharpen your thinking — Product page confirming Obsidian’s flat, markdown-only, relationship-based vault structure as described in the tutorial’s exception case









0 Comments