Token Maxxing Explained — Why It Matters
AI token budgets are exploding — and most teams have no framework for deciding whether that’s working. This tutorial walks you through a strategic lens developed by the Marketing Against the Grain hosts that reframes AI spend around measurable business outcomes. By the end, you’ll have a repeatable formula for evaluating any team’s AI usage, a department-level mapping of outcomes to apply immediately, and a clear filter for deciding which AI workflows are worth your time.
- Define the problem: token maxxing. Token maxxing is the practice of burning as many AI tokens as possible — often celebrated as a signal of ambition or sophistication — without a clear rationale tied to results. The term borrows from internet culture where “maxxing” means optimizing obsessively for a single variable. In this case, the variable is consumption itself. NVIDIA CEO Jensen Huang publicly stated he’d expect individual developers to spend $250,000 per year on tokens; that framing has filtered into team culture and budget conversations across the industry.

-
Introduce the counterframe: outcome maxxing. The alternative isn’t spending less — it’s measuring differently. Outcome maxxing asks whether AI usage is producing better results and whether the business is growing because of it. A sales rep who runs an AI prospecting agent and doubles their closed deals this month is outcome maxxing. A developer shipping more pull requests because AI is faster may or may not be, depending on whether those commits move a meaningful needle.
-
Apply the formula. The framework condenses to one equation: AI usage ÷ outcome = strategy. If a team cannot state the outcome of their AI usage in a single sentence, they don’t have a strategy — they have token maxxing. The one-sentence test is the practical gate: “We’re using AI on the blog to cut post production time from five hours to one hour” passes. “We’re using AI a lot” does not.
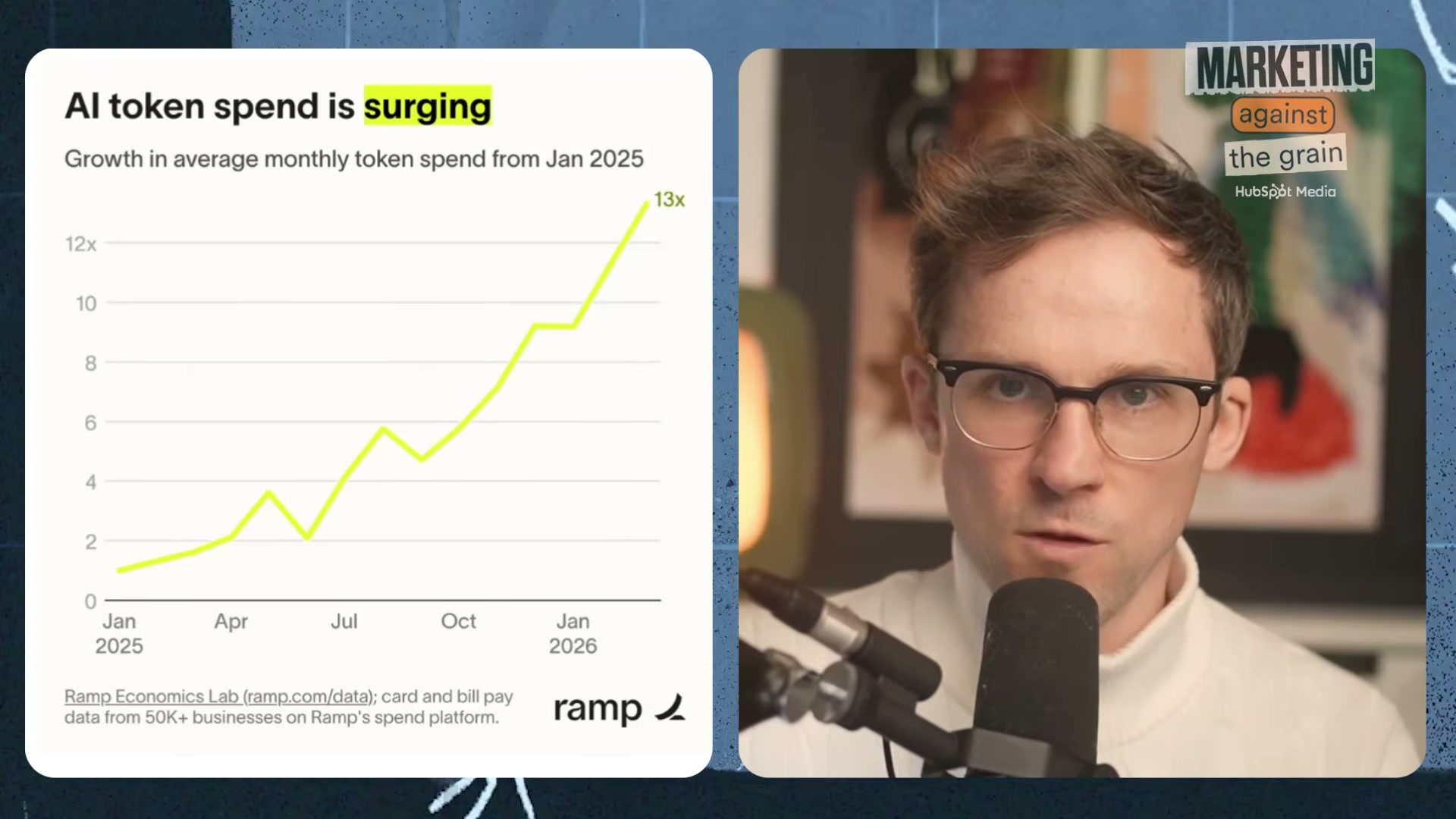
- Map AI usage to department-level outcomes. Each go-to-market function has a natural proxy metric that AI should move. For sales, the target is productivity per rep (PPR) — deals closed, pipeline generated. For support, it’s ticket deflection rate paired with CSAT scores. Marketing is the hardest to pin down: content velocity and agency spend reduction are two workable proxies, but the causal link requires deliberate measurement. Ramp’s data shows average monthly token spend grew 13x from January 2025 to January 2026 across 50,000+ businesses — the budget line is moving whether or not the outcome line follows it.
-
Set quarterly project-and-outcome targets before allocating AI access. Before any team gets broad model access, define a discrete set of projects and the outcomes each project should drive this quarter. A CMO example: integrate AI across the social media team with a target of reducing agency spend by a specific dollar amount while maintaining or improving engagement benchmarks. The outcome defines the project scope — not the other way around.
-
Apply the repeatability filter. Rebuilding a product page is a good use of AI-assisted speed. Changing a button color is not. The test: will this workflow run more than once? One-off tasks that consume significant token budget don’t compound into organizational capability. Repeatable workflows do.
-
Factor in the learning argument — carefully. Token costs today are subsidized by venture capital. Because AI companies are currently running negative margins, this may be the cheapest moment in history to develop organizational fluency with these tools. High usage now can be framed as an investment in future capability — provided that rationale is explicit, not a post-hoc justification.
-
Recognize the most dangerous profile. High token usage combined with low craft is the highest-risk position a team or individual can occupy. AI amplifies output in both directions — strong judgment produces more of the right things faster; poor judgment produces more of the wrong things faster. Token volume without skill development is not a strategy; it’s a liability at scale.
How does this compare to the official docs?
The framework here is built from practitioner intuition and real team observation — the next section grounds each of these steps in what AI platform providers, finance tooling vendors, and go-to-market research actually prescribe for measuring AI ROI.
Here’s What the Official Docs Show
The video builds a solid practitioner framework, and the platform documentation fills in several gaps — most notably around terminology, department coverage, and how outcome-based AI measurement already works in production tools. What follows works through each step in sequence.
Step 1: Token maxxing defined
Perplexity, ChatGPT, and Gemini all confirm the structural problem: each platform surfaces multiple models — and high-consumption modes like “Deep research” or “Computer” — inside a single UI. The tracking gap the tutorial names is embedded in how these products ship.

No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 2: Outcome maxxing
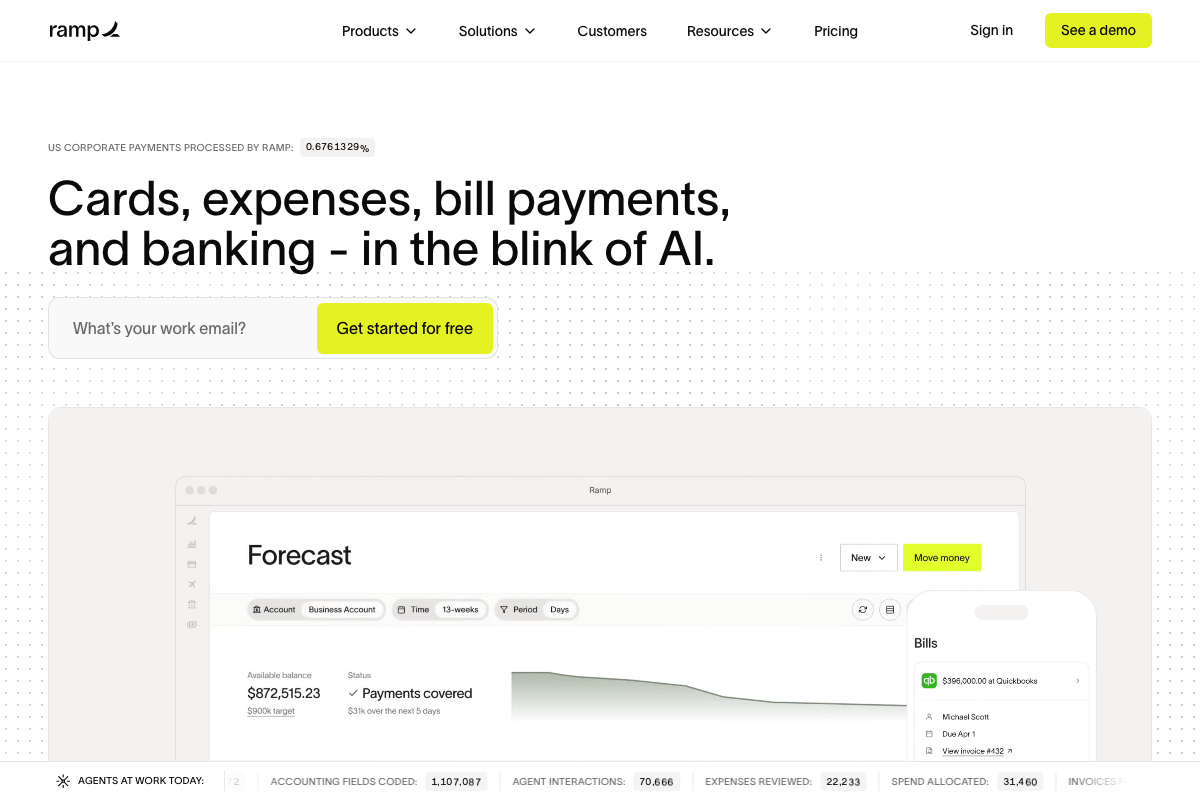
The video’s approach here matches the current docs exactly. Ramp’s live homepage counter — 1,107,087 accounting fields coded, 70,666 agent interactions, 22,233 expenses reviewed — is outcome maxxing in production. None of those numbers are tokens; all of them are business events.
Step 3: AI usage ÷ outcome = strategy
Gemini’s documented model tiers make the formula concrete: Flash is “frontier-class performance at a fraction of the cost”; Flash-Lite is the “high-volume, cost-sensitive workhorse.” Model selection is a documented lever for the exact ratio the tutorial describes.
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 4: Department-level outcome mapping
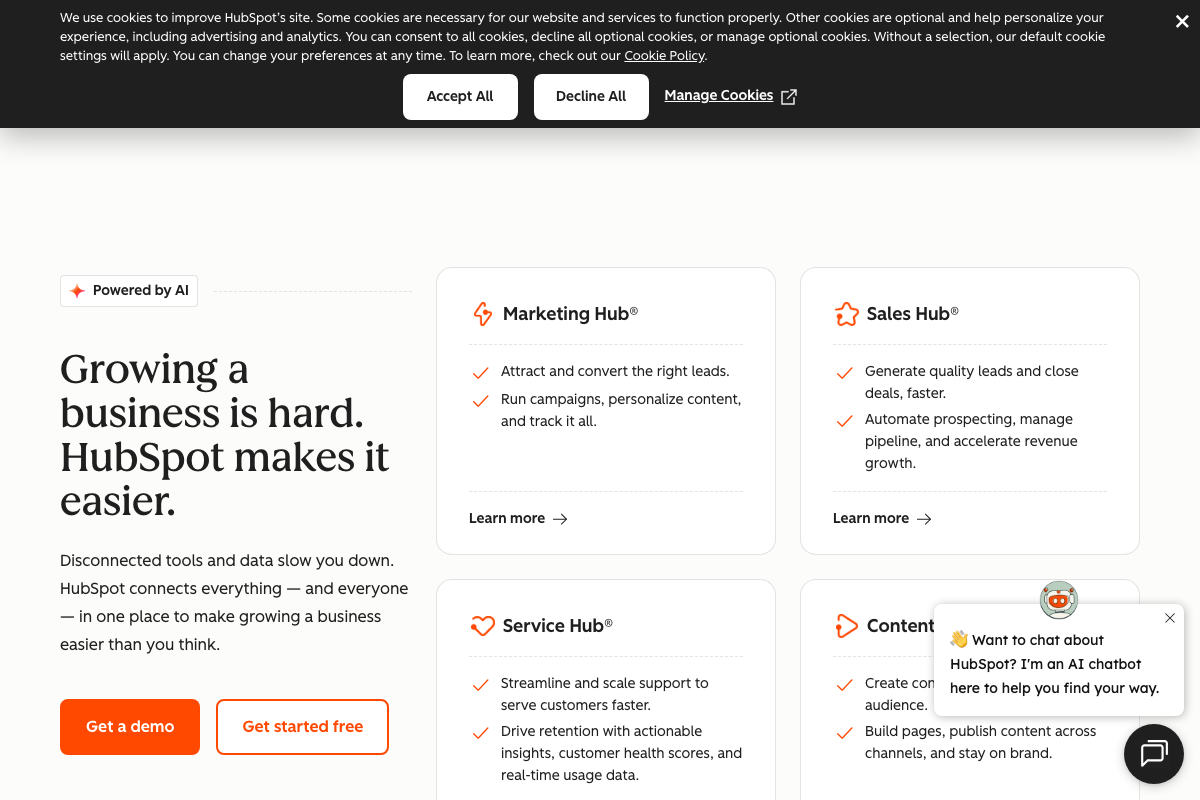
The video’s approach here matches the current docs exactly — with terminology worth noting. HubSpot confirms the three-department structure, and Sales Hub aligns on “close deals faster.” Where the docs diverge: Service Hub surfaces “customer health scores” and “real-time usage data” — not “ticket deflection” and “CSAT.” Sales Hub references “pipeline management” and “revenue growth,” not “PPR.” “Agency spend reduction” as a marketing metric does not appear in any platform documentation captured.
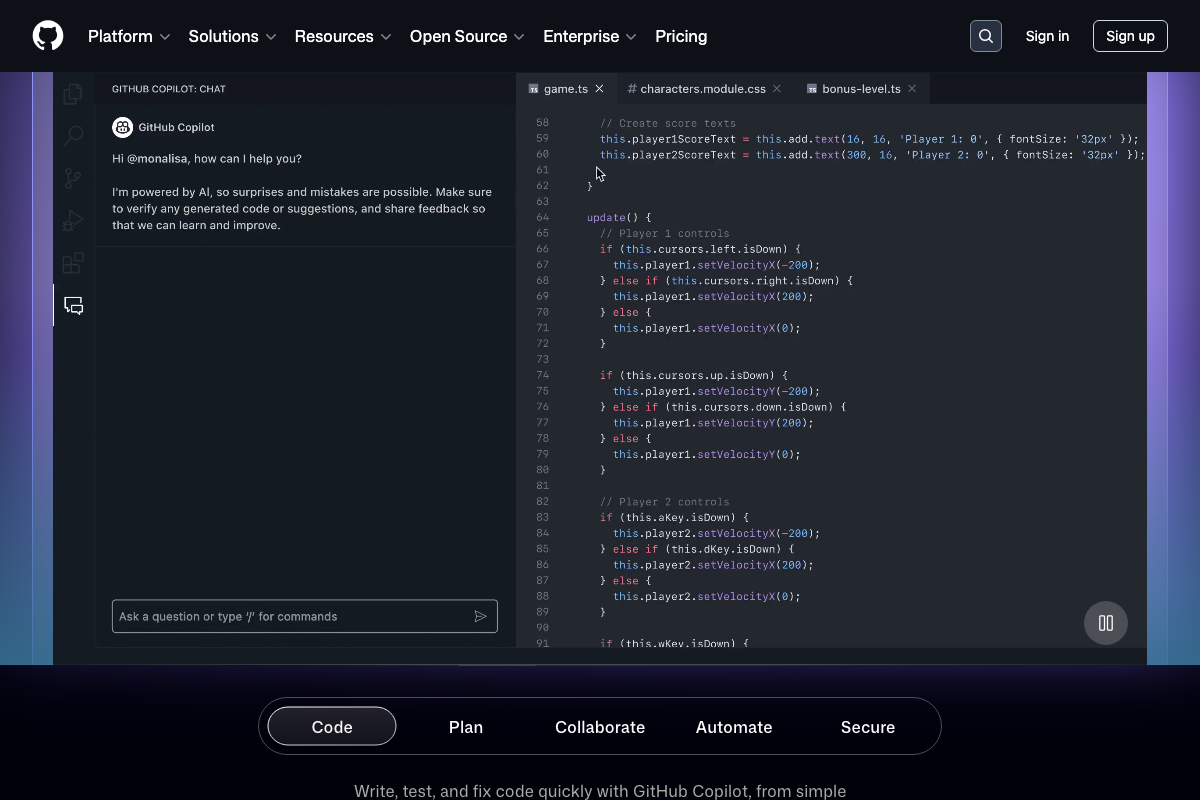
One meaningful gap: GitHub confirms engineering as a major AI-consuming department — Copilot is the platform’s primary CTA, spanning workflow tabs for Code, Plan, Collaborate, Automate, and Secure. The tutorial’s department map omits it entirely.
Step 5: Set quarterly targets before allocating access
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 6: The repeatability filter
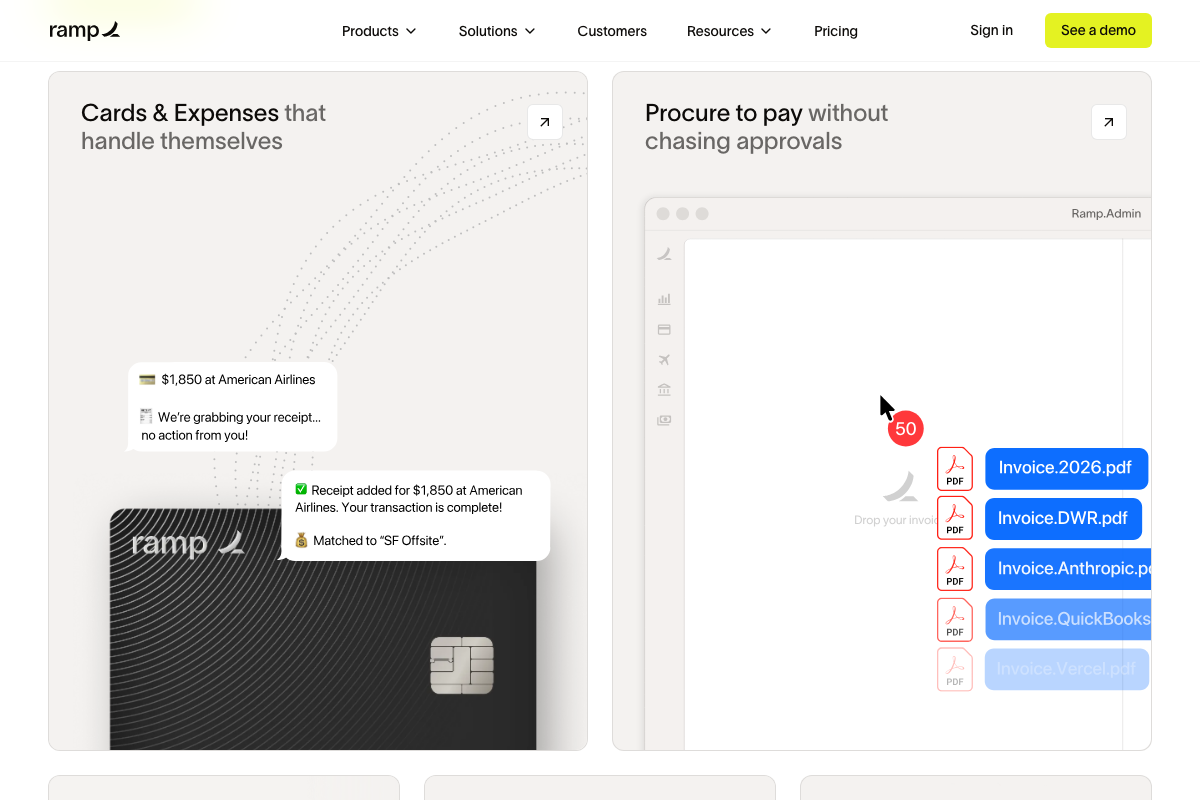
Ramp’s receipt-matching and invoice processing features are the repeatability filter in production: every transaction is a discrete, countable outcome. GitHub’s “code to deployment” workflow framing covers the same criterion in engineering.
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 7: The learning argument and token pricing
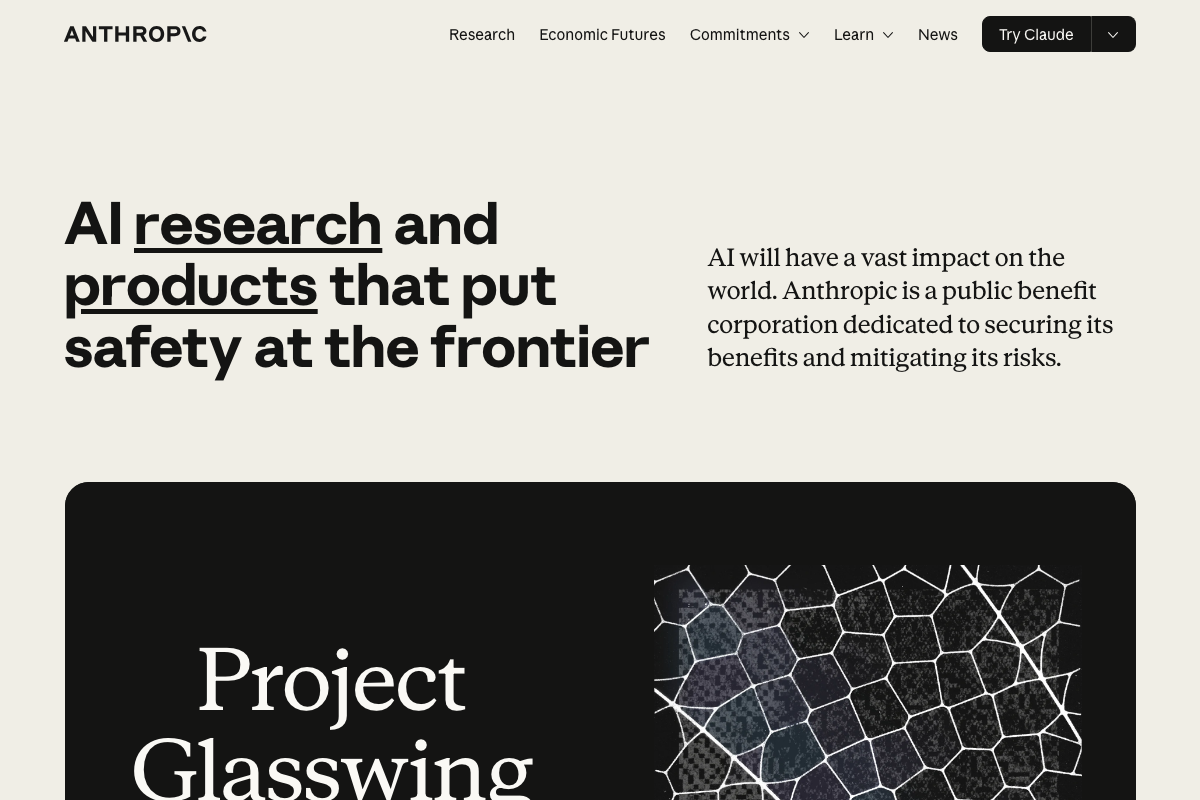
As of April 29, 2026, no token pricing data appears in any documentation captured — the “tokens are currently cheap” claim cannot be verified from these sources. On the VC subsidization framing: Anthropic’s homepage describes the company as “a public benefit corporation dedicated to securing its benefits and mitigating its risks” — a legal and organizational structure distinct from a VC-subsidized startup. Anthropic has received venture investment, but its stated framing is mission-driven, not subsidy-driven. The strategic implication for your planning is similar; the organizational context is more nuanced than the tutorial suggests.
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Step 8: High usage + low craft = highest-risk profile
Gemini’s documented “Thinking” mode adds token overhead per query in exchange for stronger reasoning — exactly the quality-vs-cost calculus step 8 describes. More tokens, potentially better output. Whether that premium is justified depends entirely on the judgment of whoever designs the workflow.
No official documentation was found for this step — proceed using the video’s approach and verify independently.
Useful Links
- Perplexity — AI search platform with a multi-model selector and agentic Computer mode, each carrying distinct token cost profiles.
- Home \ Anthropic — Anthropic’s homepage documenting its public benefit corporation structure, current Claude model releases (Opus 4.7), and the Economic Index resource.
- ChatGPT — OpenAI’s consumer AI product, surfacing Deep research and subscription pricing tiers from the main UI.
- Gemini API | Google AI for Developers — Official Gemini API documentation covering cost-tiered model selection, Thinking mode, Document Understanding, and Function Calling.
- HubSpot | Software & Tools for your Business – Homepage — HubSpot platform overview confirming its sales, marketing, and service hub architecture and the Breeze AI layer.
- Ramp — Spend management platform displaying live AI agent outcome metrics and repeatable finance workflows as concrete examples of outcome-based measurement.
- GitHub · Change is constant. GitHub keeps you ahead. · GitHub — GitHub’s homepage confirming engineering as a significant AI-consuming department through GitHub Copilot’s multi-stage, outcome-segmentable workflow capabilities.









0 Comments