AI agents can schedule meetings, draft emails, and place orders — but without knowing who they’re acting for, they’re flying blind. Nyne, a data infrastructure startup founded by Michael and Emad Fanous, just raised $5.3 million to solve exactly that problem: giving autonomous AI agents the human context they currently lack. This tutorial breaks down how Nyne’s approach works, why the “contextual gap” is the defining infrastructure challenge of agentic AI, and how practitioners can start architecting context-aware agent systems today.
What This Is
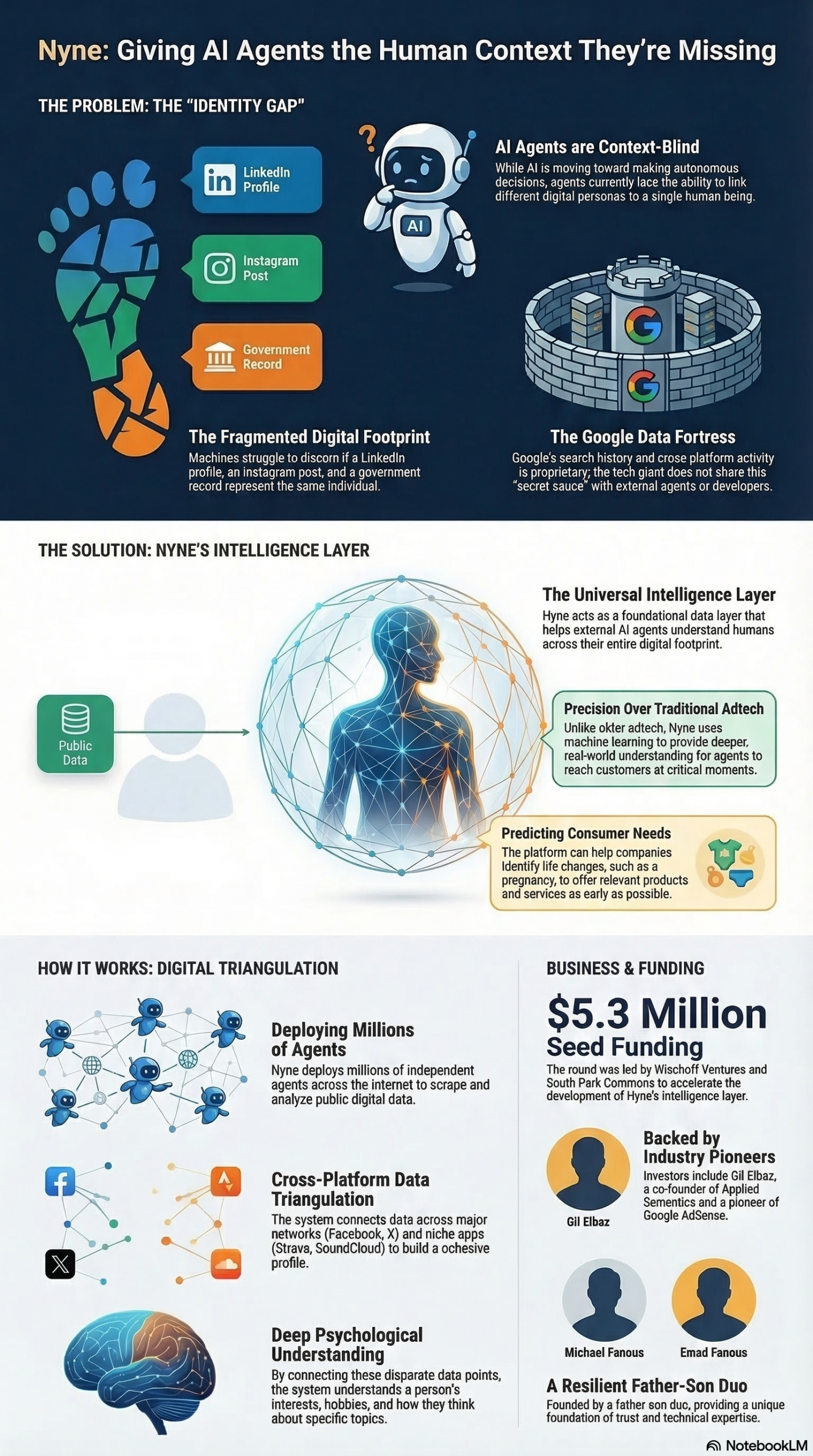
Nyne is a data infrastructure startup purpose-built to serve as the “intelligence layer” for autonomous AI agents. The company’s core thesis, as articulated by CEO Michael Fanous, is that AI agents are becoming capable of taking real-world actions — buying products, booking services, reaching out to customers — but they lack the contextual foundation to do so with genuine precision. An agent that doesn’t understand a person’s life, interests, habits, and needs is executing actions without judgment.
The founding team brings complementary backgrounds. Michael Fanous is a UC Berkeley computer science graduate and former machine learning engineer at CareRev. His father, Emad Fanous, is a veteran CTO who has led engineering organizations through multiple technology cycles. Together, they identified a structural problem in the emerging AI agent ecosystem: while large platforms like Google have solved personal context internally through decades of cross-platform data accumulation, no equivalent capability exists for the broader market of developers and companies building third-party AI agents.
Nyne’s technical approach is built around three interlocking mechanisms, as detailed in the NotebookLM research report:
Mass Deployment of Scanning Agents: Nyne deploys millions of agents to crawl the public internet, collecting data across professional platforms (LinkedIn), mainstream social networks (Facebook, X, Instagram), and niche interest and activity apps (SoundCloud, Strava). The breadth of this crawl is intentional — understanding someone’s running habits from Strava combined with their music preferences on SoundCloud and their professional trajectory on LinkedIn creates a three-dimensional profile that no single platform can provide.
Cross-Platform Triangulation: Raw data from multiple sources is meaningless without synthesis. Nyne’s infrastructure connects identity signals across platforms — resolving that the “mfanous” on LinkedIn is the same person as “@mfanous_runs” on Strava — and stitches together a unified identity graph. This cross-platform deduplication is, according to lead investor Nichole Wischoff of Wischoff Ventures, “an oddly hard problem to solve” for anyone outside of Google’s walled garden.
Machine Learning Synthesis: Once a unified identity is assembled, Nyne applies ML models to convert the fragmented data into a structured understanding of a person — their interests, hobbies, current life stage, and behavioral tendencies. As Michael Fanous described it: “Once you make all these connections, you can understand a person fairly deeply, their interests, their hobbies, and how they think about very specific things.” (NotebookLM research report)
The $5.3 million seed round was led by Wischoff Ventures and South Park Commons. Notably, the round also attracted angel investment from Gil Elbaz, the co-founder of Applied Semantics and one of the original architects of Google AdSense — a meaningful vote of confidence from someone who built the first generation of programmatic advertising infrastructure.
Why It Matters
The shift from AI assistants to AI agents is the most consequential infrastructure transition happening in software right now. Assistants answer questions. Agents take actions. And when an agent takes an action on a person’s behalf — making a purchase, sending an outreach message, scheduling a service — the quality of that action is only as good as the agent’s understanding of that person.
This is where the current generation of AI agents breaks down. Most agents today operate with shallow context: a conversation history, a few user preferences, maybe some CRM data. They do not have a holistic view of the person they’re representing. That gap produces generic, often irrelevant, and sometimes actively wrong outcomes.
Nyne’s approach matters to three distinct groups of practitioners:
AI Agent Developers building consumer-facing autonomous systems need a context layer that works before the user has provided explicit preferences. Cold-start problems — where a new user hasn’t yet trained the agent with their history — are solvable if the agent can pull a rich prior from a service like Nyne on day one.
Marketing and Growth Teams using AI agents for outreach currently rely on demographic segmentation that hasn’t fundamentally changed in twenty years: age range, location, income bracket. Nyne’s triangulation model enables behavioral-stage targeting — identifying users who are, for example, recently engaged, training for a marathon, or transitioning to a new career — enabling outreach that reflects a real moment in that person’s life rather than a statistical bucket.
Enterprise AI Platform Teams evaluating agentic infrastructure will increasingly need to audit what context their agents operate on. Nyne offers a path to that context layer without requiring enterprises to build their own cross-platform crawling and ML synthesis infrastructure from scratch — a project that would take years and significant headcount.
What makes this meaningfully different from existing adtech or data broker models is the specificity of the use case: this data is not being packaged for display advertising impression targeting. It is being structured as machine-readable context for autonomous agent decision-making — a fundamentally different API contract that requires different data precision and a different delivery architecture.
The Data
Nyne vs. Existing Data Context Solutions for AI Agents
| Capability | Traditional Data Brokers | First-Party CRM Data | Social Graph APIs | Nyne |
|---|---|---|---|---|
| Cross-platform identity resolution | Partial | No | Limited (single platform) | Yes — core feature |
| Real-time behavioral signals | No | Limited | Rate-limited | Yes |
| Niche interest app data (Strava, SoundCloud) | No | No | No | Yes |
| ML-synthesized interest profile | No | No | No | Yes |
| AI agent-native API contract | No | No | No | Yes |
| Avoids proprietary platform lock-in | Partial | No | No | Yes |
| Life-stage detection | Limited | No | No | Yes |
Source: NotebookLM research report, TechCrunch
Nyne Funding and Team Overview
| Detail | Value |
|---|---|
| Seed Funding Amount | $5.3 million |
| Lead Investors | Wischoff Ventures, South Park Commons |
| Notable Angel | Gil Elbaz (Applied Semantics / Google AdSense co-founder) |
| CEO | Michael Fanous (UC Berkeley CS, ex-CareRev ML engineer) |
| CTO | Emad Fanous (veteran CTO, co-founder’s father) |
| Announced | March 13, 2026 |
| Company Category | Data infrastructure / AI agent context layer |
Source: TechCrunch, NotebookLM research report
Step-by-Step Tutorial: Architecting a Context-Aware AI Agent Pipeline
This tutorial walks through how to design and implement an AI agent system that integrates a human context layer — using Nyne’s announced capabilities as the model. Whether you’re building a customer outreach agent, a shopping agent, or a scheduling agent, this architecture pattern applies.
Prerequisites
Before you start, you need:
– A working AI agent framework (LangChain, AutoGen, or a custom loop built on an LLM API)
– Access to a context data provider API (Nyne when available, or a staged mock for development)
– A target use case: outreach, purchasing, scheduling, or recommendation
– Basic familiarity with JSON APIs and async Python or Node.js
Phase 1: Define What Context Your Agent Actually Needs
Most teams skip this step and default to collecting everything. Don’t. Before you integrate any context layer, map out the decision tree your agent navigates and identify the specific signals that would change each branch.
Step 1: Document your agent’s decision points.
Write out every action your agent takes and the variables that determine how it takes that action. For a customer outreach agent, the decision tree might look like:
- Should I send a message to this person? → depends on: are they in the right life stage? Are they likely to be receptive right now?
- What channel should I use? → depends on: are they active on email, LinkedIn, or SMS?
- What angle should the message take? → depends on: what are their current interests? What’s their professional context?
Each decision point maps to a specific type of context signal. Document them explicitly before you write a line of integration code.
Step 2: Categorize context signals by type.
Once you have your decision points, sort the required signals into three buckets:
- Static profile data: Professional background, general interests, location (changes slowly)
- Behavioral state data: Current activities, recent engagement patterns, active hobbies (changes weekly/monthly)
- Life-stage signals: Major life transitions — new job, engagement, pregnancy, relocation (changes rarely but with high predictive value)
This categorization matters because different signals require different refresh rates, different API call cadences, and different caching strategies.
Phase 2: Integrate the Context API
Step 3: Set up the context enrichment call.
In your agent’s pre-action phase — before the agent decides what to do — add a context enrichment step. Here’s a conceptual Python implementation:
import httpx
import asyncio
async def enrich_user_context(user_identifier: str, context_api_key: str) -> dict:
"""
Calls the context layer API to retrieve a unified human context profile
for a given user identifier (email, LinkedIn URL, or phone).
"""
async with httpx.AsyncClient() as client:
response = await client.post(
"https://api.nyne.io/v1/context", # hypothetical endpoint
headers={
"Authorization": f"Bearer {context_api_key}",
"Content-Type": "application/json"
},
json={
"identifier": user_identifier,
"identifier_type": "email", # or "linkedin_url", "phone"
"fields": [
"interests",
"active_hobbies",
"professional_stage",
"life_stage_signals",
"platform_activity"
]
},
timeout=5.0
)
response.raise_for_status()
return response.json()
Step 4: Feed context into your agent’s system prompt.
Once you have the context profile, inject it into the agent’s reasoning context before action generation:
async def run_outreach_agent(user_email: str, api_key: str):
# Step 1: Retrieve human context
context = await enrich_user_context(user_email, api_key)
# Step 2: Build a context-aware system prompt
system_prompt = f"""
You are a personalized outreach agent. You are reaching out to a person
with the following verified context profile:
Professional stage: {context.get('professional_stage', 'unknown')}
Active interests: {', '.join(context.get('interests', []))}
Current hobbies: {', '.join(context.get('active_hobbies', []))}
Life stage signals: {context.get('life_stage_signals', 'none detected')}
Most active platforms: {', '.join(context.get('platform_activity', {}).keys())}
Use this context to personalize the outreach message. Do not reference
the context data explicitly — use it to inform tone, angle, and relevance.
"""
# Step 3: Run the agent with enriched context
response = await llm_client.chat(
system=system_prompt,
user="Draft a personalized outreach message for this contact."
)
return response
Phase 3: Handle Edge Cases and Data Quality
Step 5: Implement graceful degradation.
Not every person will have a rich cross-platform footprint. Some users maintain strict privacy, use pseudonyms across platforms, or are simply not present on the apps Nyne scans. Your agent must handle low-confidence or empty context profiles without breaking.
def build_context_prompt(context: dict) -> str:
confidence = context.get("confidence_score", 0)
if confidence < 0.3:
# Low confidence — use minimal context, don't over-personalize
return "Proceed with a professional, general-purpose outreach approach."
elif confidence < 0.7:
# Medium confidence — use top-level signals only
interests = context.get("interests", [])[:2]
return f"Light personalization available. Known interests: {interests}."
else:
# High confidence — full personalization
return build_full_context_prompt(context)
Step 6: Set appropriate cache TTLs.
Context data has different shelf lives depending on signal type. Caching aggressively saves API costs; caching too long means acting on stale context.
- Static profile data (professional background, core interests): cache for 7–30 days
- Behavioral state (recent activity patterns): cache for 24–72 hours
- Life-stage signals (high-value, time-sensitive): cache for 12–24 hours maximum, or real-time pull
Phase 4: Validate and Iterate
Step 7: A/B test contextual vs. non-contextual agent outputs.
Before you rely on context enrichment in production, measure its actual impact. Run a split test: half your agent interactions use the context layer, half use your baseline approach. Measure:
- Message relevance scores (if you have a human review loop)
- Downstream conversion rates (for outreach agents)
- Action completion rates (for purchasing or scheduling agents)
Step 8: Audit context-driven decisions regularly.
Any system that makes automated decisions based on inferred personal data carries compliance obligations. Depending on your jurisdiction and use case, GDPR, CCPA, and emerging AI-specific regulations may apply. Build an audit log from day one:
import datetime
import json
def log_context_decision(user_id: str, context_summary: dict, action_taken: str):
log_entry = {
"timestamp": datetime.datetime.utcnow().isoformat(),
"user_id": user_id,
"context_confidence": context_summary.get("confidence_score"),
"signals_used": context_summary.get("fields_present", []),
"action_taken": action_taken
}
# Write to your audit log store
with open("agent_audit_log.jsonl", "a") as f:
f.write(json.dumps(log_entry) + "\n")
Expected Outcome: After completing this pipeline, your AI agent will have a structured context enrichment step that feeds synthesized human profile data into every action decision. You’ll have graceful degradation for low-data users, appropriate caching, and an audit trail for compliance.
Real-World Use Cases
Use Case 1: AI-Powered Sales Outreach at Scale
Scenario: A B2B SaaS company uses an AI agent to personalize cold outreach to 50,000 prospects per month. Currently, the agent uses job title and company size as its only personalization variables — leading to generic messages with low response rates.
Implementation: Integrate a context layer like Nyne at the lead enrichment stage. Before the agent drafts each outreach sequence, pull the prospect’s interest profile, current professional transition signals, and active hobby indicators. An engineer switching jobs who also trains for triathlons receives a different message framing than a recently promoted enterprise architect who is active in cloud architecture forums. The agent uses these signals to select message angle, tone, and timing.
Expected Outcome: According to the NotebookLM research report, Nyne’s precision targets the kind of life-stage moment that makes outreach land. Teams that align message timing with genuine life transitions typically see significantly higher engagement than static demographic targeting allows.
Use Case 2: Consumer AI Shopping Agent
Scenario: A retail platform is building an AI agent that helps users discover and purchase products. The challenge is that new users haven’t built any history on the platform, making recommendation accuracy poor at launch.
Implementation: On new user signup, trigger a context enrichment call using only the user’s email address or linked social account. Retrieve interest and hobby signals — running gear if they’re on Strava, music equipment if they’re active on SoundCloud, professional attire if they’ve recently changed jobs. Pre-populate the agent’s recommendation context before the user has made a single purchase.
Expected Outcome: Cold-start problem is partially solved. The agent delivers relevant recommendations from session one. As Michael Fanous explained, the goal is for agents to understand “their interests, their hobbies, and how they think about very specific things” — exactly what a shopping agent needs on day one.
Use Case 3: Personalized Marketing Automation for Life-Stage Moments
Scenario: A consumer products company wants to reach expectant parents before competitors do — not through hospital data partnerships, but through behavioral signal detection in public data.
Implementation: Configure a context layer integration to surface life-stage signals for your marketing automation platform’s contact database. Flag contacts where life-stage inference confidence crosses a threshold. Route flagged contacts into specialized agent-driven nurture sequences with messaging and product recommendations appropriate for that transition.
Expected Outcome: As noted in the NotebookLM research report, the ability to identify specific life stages — such as a pregnancy — to market relevant products represents a high-value application of Nyne’s signal detection. This use case mirrors the precision that previously required first-party data relationships with healthcare providers or retail pharmacies.
Use Case 4: Enterprise AI Agent Context Standardization
Scenario: A large enterprise has deployed AI agents across customer service, sales, and internal HR workflows. Each agent operates on different data sources and produces inconsistent outputs for the same user. The data team needs a unified context layer that all internal agents can query.
Implementation: Deploy a context enrichment microservice as a shared internal API gateway. Each agent implementation — regardless of framework (LangChain, AutoGen, custom) — makes a standardized call to the gateway before action execution. The gateway fetches from Nyne’s API, applies your organization’s data governance policies, and returns a normalized context object. All agents operate on the same context standard.
Expected Outcome: Consistent personalization outputs across agent types. Simplified compliance auditing because all context-driven decisions flow through a single logged gateway. The NotebookLM research report highlights this as a key organizational value proposition: organizations should “prioritize the integration of a context layer to ensure agents make decisions based on a holistic view of the user rather than fragmented data points.”
Use Case 5: Developer API Product — Context-as-a-Service
Scenario: A developer tools company is building infrastructure for the AI agent ecosystem and wants to offer context enrichment as a managed service to their customers.
Implementation: Integrate Nyne’s API into your developer platform’s agent SDK. Expose a context.enrich() method in your SDK that abstracts the Nyne API call, handles caching, manages rate limits, and normalizes the output schema for your customers’ agents. Document the method with clear examples for the top five agent use cases in your platform.
Expected Outcome: Context enrichment becomes a one-line SDK call for your customers, reducing integration friction and accelerating time-to-value for agents built on your platform.
Common Pitfalls
Pitfall 1: Treating Context as a One-Time Pull
Many teams call the context enrichment API once at user creation and cache the result indefinitely. This is a mistake. A person’s interests, activities, and life stage change continuously. A contact who was training for a marathon six months ago may now be focused on recovery and injury prevention. Always implement TTL-based cache invalidation for behavioral signals and refresh life-stage signals at least every 24 hours. The NotebookLM research report emphasizes that Nyne’s value is in synthesizing current behavioral context — stale data defeats the purpose.
Pitfall 2: Over-Personalization That Feels Invasive
AI agents that reference inferred personal data too explicitly create a deeply uncomfortable user experience. If your outreach agent’s message says “I noticed you’ve been running a lot of Strava routes near downtown Denver lately,” you’ve crossed a line. The context should inform the agent’s reasoning, not be surfaced verbatim. The data lives in the system prompt, not in the output text. Build this distinction into your prompt architecture from day one.
Pitfall 3: Ignoring Confidence Scores
Context APIs return signals with varying confidence levels. Deploying the same personalization logic regardless of whether the confidence score is 0.2 or 0.9 will produce nonsensical outputs for low-data users. As outlined in the Phase 3 tutorial section, always implement tiered logic that scales personalization depth with confidence scores.
Pitfall 4: No Compliance Audit Trail
Building an agent that makes decisions based on inferred personal data without an audit log is a regulatory liability. Even for use cases that currently fall outside formal regulatory scope, industry norms are shifting fast. The code pattern in Step 8 of this tutorial is not optional — build it from the start.
Pitfall 5: Confusing Data Coverage for Data Accuracy
Nyne scans public data from platforms including Facebook, X, LinkedIn, Instagram, SoundCloud, and Strava, per the NotebookLM research report. But public data is not the same as complete data. Many users have partial or outdated profiles, privacy-restricted accounts, or are absent from several platforms entirely. Never assume that a synthesized profile represents ground truth — treat it as prior probability, not as fact.
Expert Tips
Tip 1: Layer Context Sources, Don’t Replace Them
A third-party context layer like Nyne is most powerful when combined with your own first-party data, not when used as a replacement for it. Use public-data context for cold-start enrichment and life-stage inference, then update with first-party behavioral signals as users engage with your product. The two sources reinforce each other.
Tip 2: Build Context Into the Agent’s Memory Architecture
Don’t just pass context as a one-time system prompt. Store synthesized context profiles in your agent’s long-term memory (vector store or structured DB), and update them on each enrichment refresh. This allows the agent to track context drift over time — noticing, for example, that a user’s interest profile has shifted significantly over three months — and adapting its behavior accordingly.
Tip 3: Monitor Context Attribution in Outputs
Add a lightweight evaluation loop that tags agent outputs with the context signals that influenced them. This attribution layer helps you debug personalization failures and identify which signal types are actually driving value in your specific use case. If professional stage data is consistently associated with high-quality outputs but hobby signals aren’t, deprioritize the latter in your API cost management.
Tip 4: Use Life-Stage Signals as Trigger Events, Not Scoring Inputs
Life-stage signals (new job, engagement, new baby) work best as discrete events that trigger specific agent workflows rather than as continuous scoring inputs. When a life-stage signal is detected, route the user into a purpose-built agent sequence optimized for that context. This is more architecturally precise than trying to blend life-stage signals with ongoing behavioral scores.
Tip 5: Benchmark Against Google’s Data Advantage Honestly
As the NotebookLM research report notes, Google’s internal data advantage — built from search history and cross-platform login data — is not fully replicable by any third-party service. Gil Elbaz, the AdSense co-founder and Nyne angel investor, understands this better than most. When evaluating context layer solutions, benchmark against realistic baselines: what context can you get from a cross-platform public data synthesis, and where does that still fall short? Set expectations accordingly.
FAQ
Q1: Is Nyne scraping private user data or violating platform terms of service?
Nyne focuses on public data — information users have voluntarily published across open platforms. The NotebookLM research report describes the approach as “triangulating public data across disparate platforms.” That said, every platform’s terms of service for automated crawling differ, and this is an active legal frontier. Practitioners integrating any context layer API should conduct their own review of applicable platform terms and data protection regulations in their target markets.
Q2: How does Nyne’s approach differ from traditional data brokers like Acxiom or Experian?
Traditional data brokers package demographic and credit data for financial services and display advertising use cases. Nyne’s architecture is purpose-built for AI agent decision-making: the output is a machine-readable context object for agentic systems, not a static demographic record for human campaign planners. The synthesis of cross-platform behavioral data — including niche interest apps like Strava and SoundCloud — and the ML-generated interest profile represent a meaningfully different data product designed for a different buyer.
Q3: What happens when a user isn’t findable across platforms?
As covered in the Common Pitfalls section, not every user has a substantial public digital footprint. The right architectural answer is graceful degradation: return a low-confidence signal with limited context and route those users to a non-personalized baseline agent behavior. Don’t attempt to infer deeply from thin data — the error rate on low-confidence signals is high enough to produce actively wrong personalization.
Q4: Is there a compliance framework for using inferred personal data in AI agent decisions?
Not yet a unified one. GDPR’s Article 22 on automated individual decision-making applies in the EU when decisions produce legal or significant effects. CCPA provides California residents with rights around inferred personal data used for targeted advertising. The specific question of AI agent decision-making (as opposed to advertising targeting) is not yet fully addressed in most regulatory frameworks, but the direction of travel is clearly toward stricter requirements. The audit logging pattern in this tutorial is the minimum viable compliance foundation.
Q5: When will Nyne’s API be publicly available?
As of the March 13, 2026 announcement of the $5.3M seed round, Nyne has not published a public API release timeline. The company is at seed stage, recently funded by Wischoff Ventures and South Park Commons per TechCrunch. Practitioners interested in early access should monitor the company’s communications directly. In the meantime, the architectural patterns in this tutorial apply to any context enrichment API you integrate.
Bottom Line
The contextual gap in autonomous AI agents is not a minor UX issue — it is the infrastructure problem that determines whether agentic AI delivers on its promise or produces a wave of imprecise, generic, and sometimes harmful automated actions at scale. Nyne’s $5.3M seed round, backed by Wischoff Ventures, South Park Commons, and Google AdSense co-founder Gil Elbaz, signals that the investor community recognizes this as foundational infrastructure worth funding. The technical approach — deploying millions of agents to triangulate public cross-platform data, then applying ML synthesis to generate structured human context — addresses a problem that, as Nichole Wischoff put it, is “oddly hard to solve” for anyone outside of Google. Practitioners building AI agent systems today should architect for a context layer from the beginning, not as an afterthought, because retrofitting contextual intelligence into an agent pipeline is significantly more painful than building the enrichment call into your initial agent loop. The companies that solve context first will own the personalization advantage that defines the next generation of consumer-facing AI.









0 Comments