Claude’s 1M Context Window vs. Context Rot: What the Benchmarks Actually Show
Anthropic’s general availability release of a 1 million token context window for Opus 4.6 and Sonnet 4.6 changes more than just the budget ceiling — it potentially changes how you manage context in Claude Code entirely. This tutorial walks through the benchmark evidence behind that claim, introduces the tools used to interrogate the data, and translates the numbers into a revised rule of thumb for context window management. By the end, you’ll know exactly when to clear your context and why the old 100K threshold no longer holds.
- Pull up Anthropic’s official announcement at
claude.com/blog/1m-context-ga. The page confirms that 1M context is now generally available for Opus 4.6 and Sonnet 4.6, with standard pricing applied across the full context range and a media limit expanded to 600 images or PDF pages per request.

2. Locate Anthropic’s published MRCR v2 8-needle long-context retrieval benchmark. Note the score for Opus 4.6 at the 1M token mark: 78.3. Cross-reference it against the field — GPT-5.4 at 36, Gemini 3.1 Pro at 26, Sonnet 4.5 at 18.5, and Opus 4.5 at roughly 26. The gap at 1M tokens is not marginal; it’s the difference between a usable context window and a theoretical one.

3. Interpret the drop from 256K to 1M tokens. Opus 4.6 falls roughly 14 percentage points over a 750K token span. In prior model generations, degradation at this scale was steep and often cliff-like — performance didn’t drift downward, it collapsed. A 14% drop distributed across 750K tokens represents a structurally different degradation pattern.

4. Open the Chroma context rot study to establish the baseline problem. Chroma’s research, published the prior summer, documented severe performance degradation across multiple models as input token length grew — the defining dataset that triggered aggressive context-clearing strategies across the Claude Code community. The Opus 4.6 curve is a departure from every model tested in that study.

5. Navigate to contextarena.ai and open the MRCR 8-needle leaderboard. Use the interactive tooltip to examine model scores at specific context lengths. The drop-off patterns across models tend to be roughly linear rather than exponential — performance doesn’t plateau and then fall off a cliff; it erodes gradually.

6. Derive a working rule of thumb from the available data: approximately 2% effectiveness loss per 100K tokens added in Claude Code. This is an extrapolation assuming linear degradation between the 256K and 1M data points, which the Context Arena data supports as a reasonable assumption — but not a confirmed one.
Warning: this step may differ from current official documentation — see the verified version below.
7. Update your context window management strategy. The previous guidance — clear aggressively at 100K–120K tokens — was a direct response to the Chroma findings. With Opus 4.6’s degradation curve, clearing at 200K or beyond is now defensible depending on your use case. If you can clear at 200K, do it; there’s no reason to absorb unnecessary degradation. But holding a session open past 200K for large codebases or long-running agents no longer requires the workarounds it once did.
8. Confirm plan eligibility. The 1M context window in Claude Code requires the Max, Teams, or Enterprise plan. It is not available on Pro or lower tiers.
9. Note the pricing change. Prior to this release, the API applied a token-count multiplier above roughly 200K tokens. That multiplier is gone — the per-token rate is flat across the full 1M range, which also applies to media inputs up to the new 600-image ceiling.
10. Hold the revised guidance loosely. There are no published data points between 256K and 1M tokens. The linearity assumption is reasonable, but unverified — degradation could steepen at 512K or flatten further. The rule of thumb is a starting point, not a guarantee.
How does this compare to the official docs?
Anthropic’s announcement page and benchmark data tell one side of the story — but the official documentation for Claude Code context management and the MRCR v2 methodology fill in critical gaps that the video leaves open.
Here’s What the Official Docs Show
The video builds a coherent case for raising context-clearing thresholds in Claude Code, and the underlying logic is sound — what follows adds documentation context for each step and flags the specific data points the screenshots couldn’t confirm, so you can calibrate your confidence in each claim. Where the docs are silent, we say so directly.
Step 1 — Anthropic’s announcement
Claude Sonnet 4.6’s existence is confirmed by an announcement card on Anthropic.com dated February 17, 2026, with links to a full announcement page and a separate model details page. The specific MRCR benchmark scores cited in the video are not visible on any captured Anthropic.com page — those numbers live in the full announcement, not the homepage.

No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Steps 2–3 — Benchmark scores and the 14% drop
Two label mismatches worth flagging. First, Context Arena’s leaderboard lists Claude entries as claude-sonnet-4 — no .6 version suffix appears for any Claude model in the captured data. Second, as of 2026-03-14, no model labeled GPT-5.4 appears in any leaderboard screenshot; the visible GPT-5 family is gpt-5, gpt-5.2, gpt-5.2:xhigh, and gpt-5-mini. The specific scores (78.3, 18.5) and the 14% drop calculation cannot be confirmed from the available screenshots.

No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Step 4 — Chroma context rot study
No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Step 5 — Context Arena leaderboard
Context Arena is real and does exactly what the video describes — interactive cross-model long-context comparisons with selectable context lengths. One gap: the captured screenshot shows the benchmark set to 2 (Easy) needles, not 8. As of 2026-03-14, the correct needle count visible is 2 — the video references 8, which reflects a different UI configuration. An 8-needle setting likely exists in the selector, but it is not what appears in the documentation screenshots.
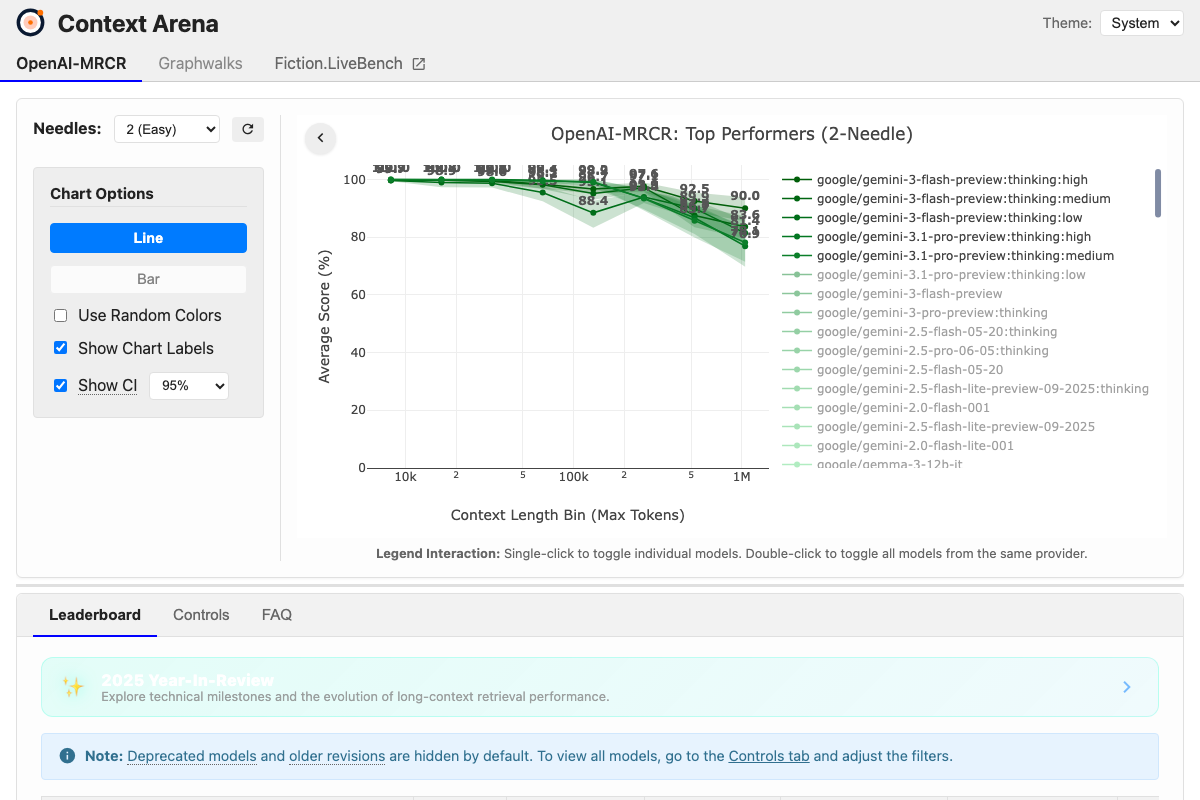

Step 6 — 2% per 100K working rule
No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Steps 7–8 — Claude Code context strategy and plan requirements
Important URL note: claude.ai/code resolves to a landing page for Cowork, a separate Claude-powered task automation product — not the Claude Code CLI. Claude Code CLI documentation lives at docs.anthropic.com/en/docs/claude-code. The Max plan is confirmed on the pricing page at $100/month; whether 1M context is gated specifically to Max or higher is plausible but not visible in the captured feature list, which is cut off in the screenshot.
No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Step 9 — Flat pricing above 200K tokens
No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Step 10 — Linearity assumption
The claude-sonnet-4 entries show N/A at 1M tokens, which is consistent with the video’s acknowledgment of missing data. No intermediate data points between 256K and 1M are visible in any screenshot — the linearity assumption remains reasonable, but unverified from the captured documentation.
No official documentation was found for this step —
proceed using the video’s approach and verify independently.
Useful Links
- Home \ Anthropic — Anthropic’s homepage, where the Claude Sonnet 4.6 announcement card (February 17, 2026) links to the full model announcement and a separate model details page.
- Context Arena — Interactive long-context retrieval benchmark leaderboard with selectable needle counts and context-length comparisons across frontier models up to 1M tokens.
- Claude Code — Resolves to the Cowork product landing page; Claude Code CLI documentation is separately maintained at
docs.anthropic.com/en/docs/claude-code.









0 Comments